首页
文章分类
源码资源
技术教程
程序软件
文创娱乐
玄学修炼
公告通知
其他页面
友情链接
闲聊灌水
随机美女
关于易航
发布
登录
注册
找回密码
首页
文章分类
源码资源
技术教程
程序软件
文创娱乐
玄学修炼
公告通知
其他页面
友情链接
闲聊灌水
随机美女
关于易航
登录
注册
找回密码
数据抓取
共4篇
请在Typecho后台-管理-分类中添加分类描述!
排序
更新
浏览
点赞
评论
运维必备!Kyanos:网络抓包牛B极了
程序软件
# Linux程序
# 网络安全
# 数据抓取
1年前
0
116
0
安卓高版本无 ROOT 抓包教程
技术教程
# 数据抓取
# 安卓逆向
1年前
0
766
0
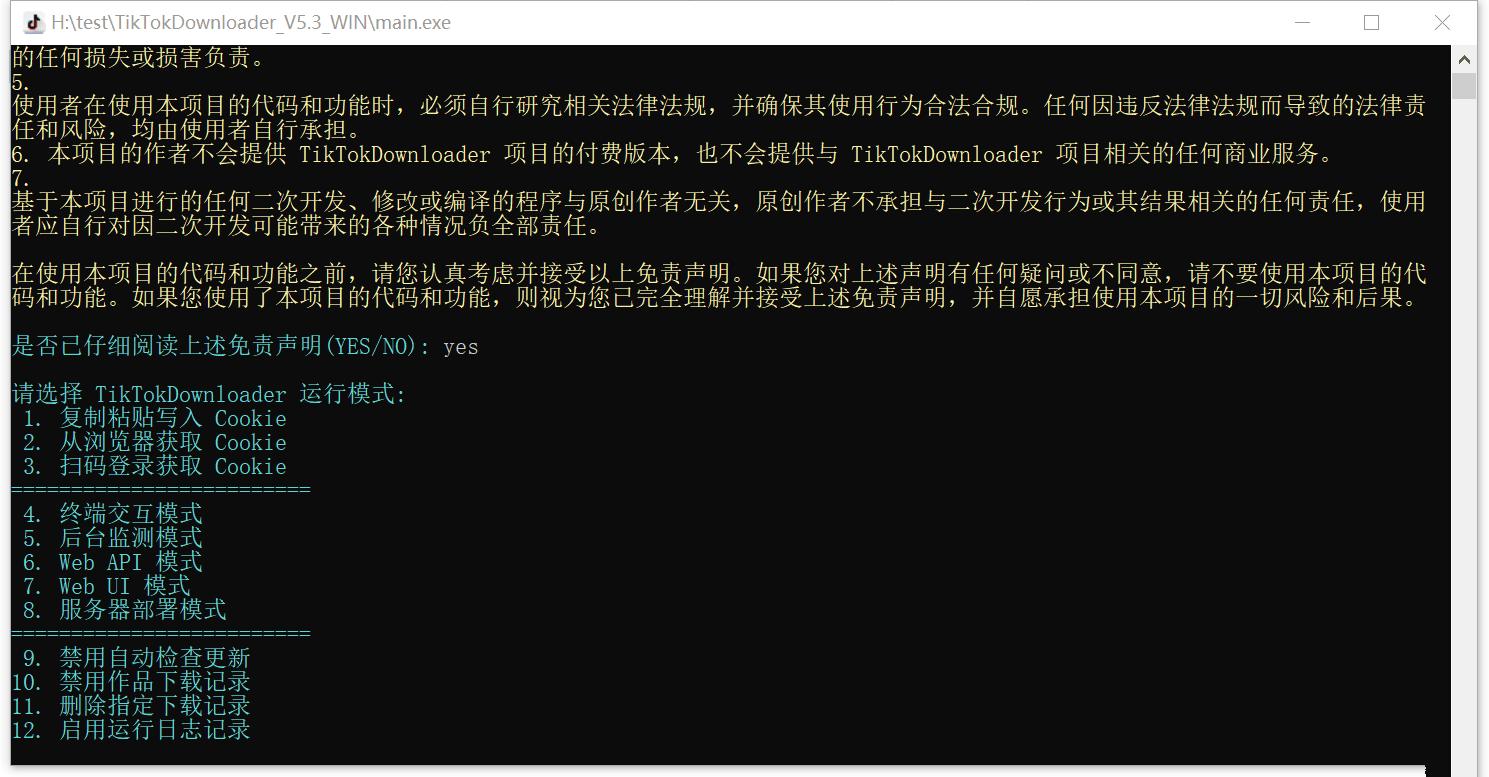
抖音采集下载工具 TikTokDownloader
源码资源
# 数据抓取
1年前
8
217
0
Python 利用无头浏览器爬虫爬取笔趣阁小说
技术教程
# Python语言
# 数据抓取
1年前
0
360
1
本站同款主题模板
Joe再续前缘主题是一款漂亮优雅的网站主题模板,功能强大,配置简单。
查看详情
在手机上浏览此页面
退出登录
您好!
确认要退出当前登录吗?
取消
确认退出