找到
180
篇与
技术教程
相关的结果
- 第 20 页
-
 Joe主题解决友链介绍高度不一BUG Joe 解决友情链接页面的友链网站介绍太长导致高度不整齐的问题,如下图 Joe主题图片 解决方法 修改 joe.global.min.css 文件,搜索关键词 desc{margin-right:10px} 。文件路径:主题目录/assets/css/joe.global.min.css 把以下代码加入到关键词里的 10px 后面 ;display:-webkit-box;-webkit-line-clamp:2;-webkit-box-orient:vertical;overflow:hidden;CSS 修改完成后的样子 .desc{margin-right:10px;display:-webkit-box;-webkit-line-clamp:2;-webkit-box-orient:vertical;overflow:hidden;}修改完后网站介绍太长会直接以...的方式省略掉,如下图 Joe主题图片
Joe主题解决友链介绍高度不一BUG Joe 解决友情链接页面的友链网站介绍太长导致高度不整齐的问题,如下图 Joe主题图片 解决方法 修改 joe.global.min.css 文件,搜索关键词 desc{margin-right:10px} 。文件路径:主题目录/assets/css/joe.global.min.css 把以下代码加入到关键词里的 10px 后面 ;display:-webkit-box;-webkit-line-clamp:2;-webkit-box-orient:vertical;overflow:hidden;CSS 修改完成后的样子 .desc{margin-right:10px;display:-webkit-box;-webkit-line-clamp:2;-webkit-box-orient:vertical;overflow:hidden;}修改完后网站介绍太长会直接以...的方式省略掉,如下图 Joe主题图片
-
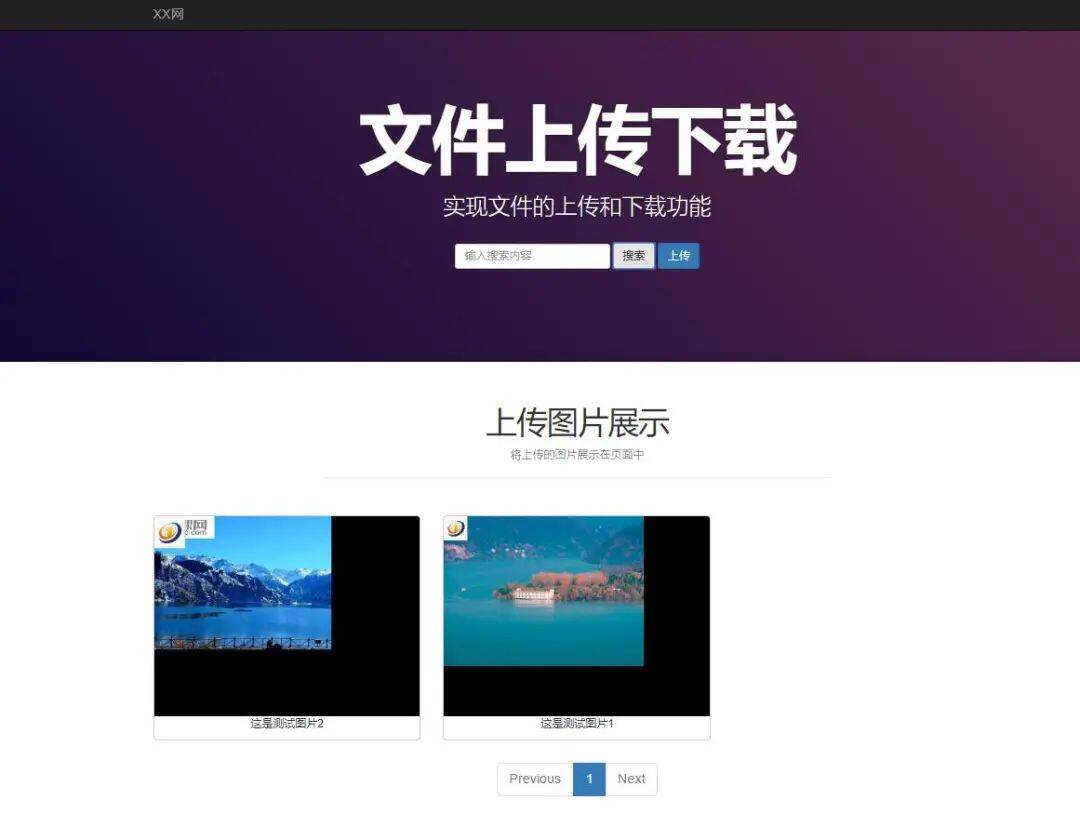
PHP实现文件上传和下载实例详解 前言 本文主要介绍用PHP上传和下载文件的例子。详细全面地阐述了文件上传的需求分析和功能实现,同时给出了使用代码。有需要的朋友可以参考一下。 在PHP中上传和下载文件是一个基本的功能。一般网站或多或少都会有这样的要求。当然也不是说所有文件都能上传,所以这个网络太不安全了。因为接触php的时间不长,所以今天的写作和练习只是一个公开的记录。 效果图 PHP实现文件上传和下载图片 PHP实现文件上传和下载图片 首先是封装好的图片类(缩放及生成水印) 1、GDBasic.php <?php /** * GDBasic.php * description GD基础类 */ namespace test\Lib; class GDBasic { protected static $_check = false; //检查服务器环境中gd库 public static function check() { //当静态变量不为false if (static::$_check) { return true; } //检查gd库是否加载 if (!function_exists("gd_info")) { throw new \Exception('GD is not exists'); } //检查gd库版本 $version = ''; $info = gd_info(); if (preg_match("/\\d+\\.\\d+(?:\\.\\d+)?/", $info["GD Version"], $matches)) { $version = $matches[0]; } //当gd库版本小于2.0.1 if (!version_compare($version, '2.0.1', '>=')) { throw new \Exception("GD requires GD version '2.0.1' or greater, you have " . $version); } self::$_check = true; return self::$_check; } }2、Image.php <?php /** * Image.php * description 图像类 */ namespace test\Lib; require_once 'GDBasic.php'; class Image extends GDBasic { protected $_width; protected $_height; protected $_im; protected $_type; protected $_mime; protected $_real_path; public function __construct($file) { //检查GD库 self::check(); $imageInfo = $this->createImageByFile($file); $this->_width = $imageInfo['width']; $this->_height = $imageInfo['height']; $this->_im = $imageInfo['im']; $this->_type = $imageInfo['type']; $this->_real_path = $imageInfo['real_path']; $this->_mime = $imageInfo['mime']; } /** * 根据文件创建图像 * @param $file * @return array * @throws \Exception */ public function createImageByFile($file) { //检查文件是否存在 if (!file_exists($file)) { throw new \Exception('file is not exits'); } //获取图像信息 $imageInfo = getimagesize($file); $realPath = realpath($file); if (!$imageInfo) { throw new \Exception('file is not image file'); } switch ($imageInfo[2]) { case IMAGETYPE_GIF: $im = imagecreatefromgif($file); break; case IMAGETYPE_JPEG: $im = imagecreatefromjpeg($file); break; case IMAGETYPE_PNG: $im = imagecreatefrompng($file); break; default: throw new \Exception('image file must be png,jpeg,gif'); } return array( 'width' => $imageInfo[0], 'height' => $imageInfo[1], 'type' => $imageInfo[2], 'mime' => $imageInfo['mime'], 'im' => $im, 'real_path' => $realPath, ); } /** * 缩略图 * @param int $width 缩略图高度 * @param int $height 缩略图宽度 * @return $this * @throws \Exception */ public function resize($width, $height) { if (!is_numeric($width) || !is_numeric($height)) { throw new \Exception('image width or height must be number'); } //根据传参的宽高获取最终图像的宽高 $srcW = $this->_width; $srcH = $this->_height; if ($width <= 0 || $height <= 0) { $desW = $srcW; //缩略图高度 $desH = $srcH; //缩略图宽度 } else { $srcP = $srcW / $srcH; //宽高比 $desP = $width / $height; if ($width > $srcW) { if ($height > $srcH) { $desW = $srcW; $desH = $srcH; } else { $desH = $height; $desW = round($desH * $srcP); } } else { if ($desP > $srcP) { $desW = $width; $desH = round($desW / $srcP); } else { $desH = $height; $desW = round($desH * $srcP); } } } //PHP版本小于5.5 if (version_compare(PHP_VERSION, '5.5.0', '<')) { $desIm = imagecreatetruecolor($desW, $desH); if (imagecopyresampled($desIm, $this->_im, 0, 0, 0, 0, $desW, $desH, $srcW, $srcH)) { imagedestroy($this->_im); $this->_im = $desIm; $this->_width = imagesx($this->_im); $this->_height = imagesy($this->_im); } } else { if ($desIm = imagescale($this->_im, $desW, $desH)) { $this->_im = $desIm; $this->_width = imagesx($this->_im); $this->_height = imagesy($this->_im); } } return $this; } /** * 根据百分比生成缩略图 * @param int $percent 1-100 * @return Image * @throws \Exception */ public function resizeByPercent($percent) { if (intval($percent) <= 0) { throw new \Exception('percent must be gt 0'); } $percent = intval($percent) > 100 ? 100 : intval($percent); $percent = $percent / 100; $desW = $this->_width * $percent; $desH = $this->_height * $percent; return $this->resize($desW, $desH); } /** * 图像旋转 * @param $degree * @return $this */ public function rotate($degree) { $degree = 360 - intval($degree); $back = imagecolorallocatealpha($this->_im, 0, 0, 0, 127); $im = imagerotate($this->_im, $degree, $back, 1); imagesavealpha($im, true); imagedestroy($this->_im); $this->_im = $im; $this->_width = imagesx($this->_im); $this->_height = imagesy($this->_im); return $this; } /** * 生成水印 * @param file $water 水印图片 * @param int $pct 透明度 * @return $this */ public function waterMask($water = '', $pct = 60) { //根据水印图像文件生成图像资源 $waterInfo = $this->createImageByFile($water); imagecopymerge(); //销毁$this->_im $this->_im = $waterInfo['im']; $this->_width = imagesx($this->_im); $this->_height = imagesy($this->_im); return $this; } /** * 图片输出 * @return bool */ public function show() { header('Content-Type:' . $this->_mime); if ($this->_type == 1) { imagegif($this->_im); return true; } if ($this->_type == 2) { imagejpeg($this->_im, null, 80); return true; } if ($this->_type == 3) { imagepng($this->_im); return true; } } /** * 保存图像文件 * @param $file * @param null $quality * @return bool * @throws \Exception */ public function save($file, $quality = null) { //获取保存目的文件的扩展名 $ext = pathinfo($file, PATHINFO_EXTENSION); $ext = strtolower($ext); if (!$ext || !in_array($ext, array('jpg', 'jpeg', 'gif', 'png'))) { throw new \Exception('image save file must be jpg ,png,gif'); } if ($ext === 'gif') { imagegif($this->_im, $file); return true; } if ($ext === 'jpeg' || $ext === 'jpg') { if ($quality > 0) { if ($quality < 1) { $quality = 1; } if ($quality > 100) { $quality = 100; } imagejpeg($this->_im, $file, $quality); } else { imagejpeg($this->_im, $file); } return true; } if ($ext === 'png') { imagepng($this->_im, $file); return true; } } }style样式不是重点,先不放了 然后是ajax类封装的文件:ajax.js let $ = new class { constructor() { this.xhr = new XMLHttpRequest(); this.xhr.onreadystatechange = () => { if (this.xhr.readyState == 4 && this.xhr.status == 200) { // process response text let response = this.xhr.responseText; if (this.type == "json") { response = JSON.parse(response); } this.callback(response); } } } get(url, parameters, callback, type = "text") { // url = test.php?username=zhangsan&age=20 // parameters = {"username": "zhangsan", "age": 20} let data = this.parseParameters(parameters); if (data.length > 0) { url += "?" + data; } this.type = type; this.callback = callback; this.xhr.open("GET", url, true); this.xhr.send(); } post(url, parameters, callback, type = "text") { let data = this.parseParameters(parameters); this.type = type; this.callback = callback; this.xhr.open("POST", url, true); this.xhr.setRequestHeader("Content-Type", "application/x-www-form-urlencoded"); this.xhr.send(data); } parseParameters(parameters) { // username=zhangsan&age=20 let buildStr = ""; for (let key in parameters) { let str = key + "=" + parameters[key]; buildStr += str + "&"; } return buildStr.substring(0, buildStr.length - 1); } };1、首页文件:index.php <!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <!-- 上述3个meta标签*必须*放在最前面,任何其他内容都*必须*跟随其后!--> <title>文件上传和下载</title> <!-- Bootstrap --> <link href="style/css/bootstrap.min.css" rel="stylesheet"> <link href="style/css/site.min.css" rel="stylesheet"> <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css"> <style> .projects .thumbnail .caption { height: auto; max-width: auto; } .image { margin: 10px auto; border-radius: 5px; overflow: hidden; border: 1px solid #CCC; } .image .caption P { text-align: center; } </style> </head> <body> <!--导航栏--> <div class="navbar navbar-inverse navbar-fixed-top"> <div class="container"> <div class="navbar-header"> <button class="navbar-toggle collapsed" type="button" data-toggle="collapse" data-target=".navbar-collapse"> <span class="sr-only">Toggle navigation</span> <span class="icon-bar"></span> <span class="icon-bar"></span> <span class="icon-bar"></span> </button> <a class="navbar-brand hidden-sm" href="" onclick="_hmt.push(['_trackEvent', 'navbar', 'click', 'navbar-首页'])">XX网</a> </div> <div class="navbar-collapse collapse" role="navigation"> <ul class="nav navbar-nav"> <li class="hidden-sm hidden-md"> <a href="" target="_blank"></a> </li> <li> <a href="" target="_blank"></a> </li> </ul> </div> </div> </div> <!--导航栏结束--> <!--巨幕--> <div class="jumbotron masthead"> <div class="container"> <h1>文件上传下载</h1> <h2>实现文件的上传和下载功能</h2> <p class="masthead-button-links"> <form class="form-inline" onsubmit="return false;"> <div class="form-group"> <input type="search" class="form-control keywords" id="exampleInputName2" placeholder="输入搜索内容" name="keywords" value=""> <button class="btn btn-default searchBtn" type="submit">搜索</button> <button type="button" class="btn btn-primary btn-default" data-toggle="modal" data-target="#myModal"> 上传 </button> </div> </form> </p> </div> </div> <!--巨幕结束--> <!-- 模态框 --> <div class="modal fade" id="myModal" tabindex="-1" role="dialog" aria-labelledby="myModalLabel"> <div class="modal-dialog" role="document"> <form class="form-inline" action="upload_class.php" method="post" enctype="multipart/form-data"> <input type="hidden" name="MAX_FILE_SIZE" value="10240000" /> <div class="modal-content"> <div class="modal-header"> <button type="button" class="close" data-dismiss="modal" aria-label="Close"><span aria-hidden="true">×</span></button> <h4 class="modal-title" id="myModalLabel">上传图片</h4> </div> <div class="modal-body"> <p>选择图片:</p><input type="file" id="image" name="test_pic[]"> <br /> <p>图片描述:</p><textarea class="form-control" cols="75" name="description" id="info"></textarea> <br /><br /> <p> 是否添加水印: <select name="mark"> <option value="1">添加</option> <option value="0">不添加</option> </select> </p> <br /> <p> 图片宽度比例: <select name="scale"> <option value="800*600">800*600</option> <option value="600*450">600*450</option> <option value="400*300">400*300</option> </select> </p> </div> <div class="modal-footer"> <button type="submit" class="btn btn-default" name="submit" id="submit" onclick="show(this)">上传</button> <button type="reset" class="btn btn-primary">重置</button> </div> </div> </form> </div> </div> <!--模态框结束--> <div class="container projects"> <div class="projects-header page-header"> <h2>上传图片展示</h2> <p>将上传的图片展示在页面中</p> </div> <div class="row pic_body"> <!-- 使用js显示图片 --> </div> <!--分页--> <nav aria-label="Page navigation" style="text-align:center"> <ul class="pagination pagination-lg"> <!-- 使用js显示页码 --> </ul> </nav> </div> <footer class="footer container"> <div class="row footer-bottom"> <ul class="list-inline text-center"> <h4><a href="class.test.com" target="_blank">class.test.com</a> | XX网</h4> </ul> </div> </footer> <!-- jQuery (necessary for Bootstrap's JavaScript plugins) --> <script src="style/js/jquery.min.js"></script> <!-- Include all compiled plugins (below), or include individual files as needed --> <script src="style/js/bootstrap.min.js"></script> <script type="text/JavaScript"> function show(){ if(document.getElementById("image").value == ''){ alert('请选择图片'); } if(document.getElementById("info").value == ''){ alert('请输入图片描述'); } } </script> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.2.1.slim.min.js" integrity="sha384-KJ3o2DKtIkvYIK3UENzmM7KCkRr/rE9/Qpg6aAZGJwFDMVNA/GpGFF93hXpG5KkN" crossorigin="anonymous"> </script> <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.12.9/umd/popper.min.js" integrity="sha384-ApNbgh9B+Y1QKtv3Rn7W3mgPxhU9K/ScQsAP7hUibX39j7fakFPskvXusvfa0b4Q" crossorigin="anonymous"> </script> <script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0/js/bootstrap.min.js" integrity="sha384-JZR6Spejh4U02d8jOt6vLEHfe/JQGiRRSQQxSfFWpi1MquVdAyjUar5+76PVCmYl" crossorigin="anonymous"> </script> <script src="style/js/Ajax.js"></script> <script> let pageNo = 1; let kws = ''; let searchBtn = document.getElementsByClassName('searchBtn')[0]; searchBtn.onclick = function() { let search = document.getElementsByClassName('keywords')[0]; let keywords = search.value; requestData(pageNo, keywords); kws = keywords; }; let requestPage = function(page) { requestData(page, kws); pageNo = page; }; let requestData = function(page_number, keywords) { let pagination = document.getElementsByClassName('pagination')[0]; let pic_body = document.getElementsByClassName('pic_body')[0]; pic_body.innerHTML = '<p style="text-align:center"><i class="fa fa-spinner fa-spin" style="font-size:24px"></i> 加载中...</p>'; $.get('search.php', { "page": page_number, "keywords": keywords }, function(res) { let divs = ''; if (res.code == 1) { // 请求成功 res.rows.forEach(function(item) { let div = '<div class="col-sm-6 col-md-3 col-lg-4"><div class="image"><a href="' + item .path + '" target="_blank"><img class="img-responsive" src="' + item.path + '" ></a><div class="caption"><p>' + item.info + '</p></div></div></div>'; divs += div; }); pic_body.innerHTML = divs; // 加载页码导航 // previous let previousBtn = ''; if (res.page_number == 1) { previousBtn = '<li class="page-item disabled"><a class="page-link" href="javascript:requestPage(' + (res.page_number - 1) + ');">Previous</a></li>'; } else { previousBtn = '<li class="page-item"><a class="page-link" href="javascript:requestPage(' + (res .page_number - 1) + ');">Previous</a></li>'; } // next let nextBtn = ''; if (res.page_total == res.page_number) { nextBtn = '<li class="page-item disabled"><a class="page-link" href="javascript:requestPage(' + (res.page_number + 1) + ');">Next</a></li>'; } else { nextBtn = '<li class="page-item"><a class="page-link" href="javascript:requestPage(' + ( res.page_number + 1) + ');">Next</a></li>' } let pages = previousBtn; for (let page = 1; page <= res.page_total; page++) { let active = ''; if (page == res.page_number) { active = 'active'; } pages += '<li class="page-item ' + active + '"><a class="page-link" href="javascript:requestPage(' + page + ');">' + page + '</a></li>'; } pages += nextBtn; pagination.innerHTML = pages; } }, 'json'); }; requestData(1, ''); </script> </body> </html>2、图片相关功能处理:upload_class.php <?php //接收传过来的数据 $description = $_POST['description']; //描述 $mark = $_POST['mark']; //水印 $scale = $_POST['scale']; //比例 800*600 $path = ''; //图片存储路径 //根据比例获取宽高 $width = substr($scale, 0, 3); //800 $height = substr($scale, 4, 3); //600 //上传图片并存储 require('UploadFile.php'); $upload = new UploadFile('test_pic'); $upload->setDestinationDir('./uploads'); $upload->setAllowMime(['image/jpeg', 'image/gif', 'image/png']); $upload->setAllowExt(['gif', 'jpeg', 'jpg', 'png']); $upload->setAllowSize(2 * 1024 * 1024); if ($upload->upload()) { $filename = $upload->getFileName()[0]; $dir = $upload->getDestinationDir(); $path = $dir . '/' . $filename; //图片存储的实际路径 } else { var_dump($upload->getErrors()); } //根据比例调整图像 require_once './lib/Image.php'; $image = new \test\Lib\Image($path); //放大并保存 $image->resize($width, $height)->save($path); $info = getimagesize($path); //根据不同的图像type 来创建图像 switch ($info[2]) { case 1: //IMAGETYPE_GIF $image = imagecreatefromgif($path); break; case IMAGETYPE_JPEG: $image = imagecreatefromjpeg($path); break; case 3: $image = imagecreatefrompng($path); break; default: echo '图像格式不支持'; break; } //添加水印 if ($mark == 1) { $logo = imagecreatefrompng('./uploads/logo.png'); //添加水印 imagecopy($image, $logo, 0, 0, 0, 0, imagesx($logo), imagesy($logo)); //header('Content-type:image/png'); imagejpeg($image, $path); } $dst_image = imagecreatetruecolor($width, $height); //拷贝源图像左上角起始 imagecopy($dst_image, $image, 0, 0, 0, 0, $width, $height); imagejpeg($dst_image, $path); //存入数据库 $servername = "localhost"; $username = "root"; $password = "123456"; $dbname = "pic"; try { $conn = new PDO("mysql:host=$servername;dbname=$dbname", $username, $password); // 设置 PDO 错误模式,用于抛出异常 $conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); $sql = "INSERT INTO pic(`path`, `mark`, `scale`,`info`) VALUES ('$path', '$mark', '$scale','$description')"; // 使用 exec() ,没有结果返回 $conn->exec($sql); exit("<script>alert(\"图片上传成功!\");window.location=\"index.php\";</script>"); } catch (PDOException $e) { echo $sql . "<br>" . $e->getMessage(); }3、封装好的文件上传类:UploadFile.php <?php /** * Created by http://blog.yihang.info * User: 易航 * Date: 2022/7/03 * Time: 22:01 */ class UploadFile { const UPLOAD_ERROR = [ UPLOAD_ERR_INI_SIZE => '文件大小超出了php.ini当中的upload_max_filesize的值', UPLOAD_ERR_FORM_SIZE => '文件大小超出了MAX_FILE_SIZE的值', UPLOAD_ERR_PARTIAL => '文件只有部分被上传', UPLOAD_ERR_NO_FILE => '没有文件被上传', UPLOAD_ERR_NO_TMP_DIR => '找不到临时目录', UPLOAD_ERR_CANT_WRITE => '写入磁盘失败', UPLOAD_ERR_EXTENSION => '文件上传被扩展阻止', ]; /** * @var */ protected $field_name; /** * @var string */ protected $destination_dir; /** * @var array */ protected $allow_mime; /** * @var array */ protected $allow_ext; /** * @var */ protected $file_org_name; /** * @var */ protected $file_type; /** * @var */ protected $file_tmp_name; /** * @var */ protected $file_error; /** * @var */ protected $file_size; /** * @var array */ protected $errors; /** * @var */ protected $extension; /** * @var */ protected $file_new_name; /** * @var float|int */ protected $allow_size; /** * UploadFile constructor. * @param $keyName * @param string $destinationDir * @param array $allowMime * @param array $allowExt * @param float|int $allowSize */ public function __construct($keyName, $destinationDir = './uploads', $allowMime = ['image/jpeg', 'image/gif'], $allowExt = ['gif', 'jpeg'], $allowSize = 2 * 1024 * 1024) { $this->field_name = $keyName; $this->destination_dir = $destinationDir; $this->allow_mime = $allowMime; $this->allow_ext = $allowExt; $this->allow_size = $allowSize; } /** * @param $destinationDir */ public function setDestinationDir($destinationDir) { $this->destination_dir = $destinationDir; } /** * @param $allowMime */ public function setAllowMime($allowMime) { $this->allow_mime = $allowMime; } /** * @param $allowExt */ public function setAllowExt($allowExt) { $this->allow_ext = $allowExt; } /** * @param $allowSize */ public function setAllowSize($allowSize) { $this->allow_size = $allowSize; } /** * @return bool */ public function upload() { // 判断是否为多文件上传 $files = []; if (is_array($_FILES[$this->field_name]['name'])) { foreach ($_FILES[$this->field_name]['name'] as $k => $v) { $files[$k]['name'] = $v; $files[$k]['type'] = $_FILES[$this->field_name]['type'][$k]; $files[$k]['tmp_name'] = $_FILES[$this->field_name]['tmp_name'][$k]; $files[$k]['error'] = $_FILES[$this->field_name]['error'][$k]; $files[$k]['size'] = $_FILES[$this->field_name]['size'][$k]; } } else { $files[] = $_FILES[$this->field_name]; } foreach ($files as $key => $file) { // 接收$_FILES参数 $this->setFileInfo($key, $file); // 检查错误 $this->checkError($key); // 检查MIME类型 $this->checkMime($key); // 检查扩展名 $this->checkExt($key); // 检查文件大小 $this->checkSize($key); // 生成新的文件名称 $this->generateNewName($key); if (count((array)$this->getError($key)) > 0) { continue; } // 移动文件 $this->moveFile($key); } if (count((array)$this->errors) > 0) { return false; } return true; } /** * @return array */ public function getErrors() { return $this->errors; } /** * @param $key * @return mixed */ protected function getError($key) { return $this->errors[$key]; } protected function setFileInfo($key, $file) { // $_FILES name type temp_name error size $this->file_org_name[$key] = $file['name']; $this->file_type[$key] = $file['type']; $this->file_tmp_name[$key] = $file['tmp_name']; $this->file_error[$key] = $file['error']; $this->file_size[$key] = $file['size']; } /** * @param $key * @param $error */ protected function setError($key, $error) { $this->errors[$key][] = $error; } /** * @param $key * @return bool */ protected function checkError($key) { if ($this->file_error > UPLOAD_ERR_OK) { switch ($this->file_error) { case UPLOAD_ERR_INI_SIZE: case UPLOAD_ERR_FORM_SIZE: case UPLOAD_ERR_PARTIAL: case UPLOAD_ERR_NO_FILE: case UPLOAD_ERR_NO_TMP_DIR: case UPLOAD_ERR_CANT_WRITE: case UPLOAD_ERR_EXTENSION: $this->setError($key, self::UPLOAD_ERROR[$this->file_error]); return false; } } return true; } /** * @param $key * @return bool */ protected function checkMime($key) { if (!in_array($this->file_type[$key], $this->allow_mime)) { $this->setError($key, '文件类型' . $this->file_type[$key] . '不被允许!'); return false; } return true; } /** * @param $key * @return bool */ protected function checkExt($key) { $this->extension[$key] = pathinfo($this->file_org_name[$key], PATHINFO_EXTENSION); if (!in_array($this->extension[$key], $this->allow_ext)) { $this->setError($key, '文件扩展名' . $this->extension[$key] . '不被允许!'); return false; } return true; } /** * @return bool */ protected function checkSize($key) { if ($this->file_size[$key] > $this->allow_size) { $this->setError($key, '文件大小' . $this->file_size[$key] . '超出了限定大小' . $this->allow_size); return false; } return true; } /** * @param $key */ protected function generateNewName($key) { $this->file_new_name[$key] = uniqid() . '.' . $this->extension[$key]; } /** * @param $key * @return bool */ protected function moveFile($key) { if (!file_exists($this->destination_dir)) { mkdir($this->destination_dir, 0777, true); } $newName = rtrim($this->destination_dir, '/') . '/' . $this->file_new_name[$key]; if (is_uploaded_file($this->file_tmp_name[$key]) && move_uploaded_file($this->file_tmp_name[$key], $newName)) { return true; } $this->setError($key, '上传失败!'); return false; } /** * @return mixed */ public function getFileName() { return $this->file_new_name; } /** * @return string */ public function getDestinationDir() { return $this->destination_dir; } /** * @return mixed */ public function getExtension() { return $this->extension; } /** * @return mixed */ public function getFileSize() { return $this->file_size; } }4、搜索功能实现:search.php <?php // 接收请求数据 $pageNo = $_GET['page'] ?? 1; $pageSize = 9; // 接收查询参数 $keywords = $_GET['keywords'] ?? ''; $data = []; //模拟加载中的图标sleep(3); try { $pdo = new PDO( 'mysql:host=localhost:3306;dbname=pic', 'root', '123456', [PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION] ); // 请求mysql 查询记录总数 $sql = 'SELECT count(*) AS aggregate FROM pic'; if (strlen($keywords) > 0) { $sql .= ' WHERE info like ?'; } $stmt = $pdo->prepare($sql); if (strlen($keywords) > 0) { $stmt->bindValue(1, '%' . $keywords . '%', PDO::PARAM_STR); } $stmt->execute(); $total = $stmt->fetch(PDO::FETCH_ASSOC)['aggregate']; // 计算最大页码,设置页码边界 $minPage = 1; $maxPage = ceil($total / $pageSize); // 3.6 $pageNo = max($pageNo, $minPage); $pageNo = min($pageNo, $maxPage); $offset = ($pageNo - 1) * $pageSize; $sql = "SELECT `path`,`info` FROM pic "; if (strlen($keywords) > 0) { $sql .= ' WHERE info like ?'; } $sql .= 'ORDER BY id DESC LIMIT ?, ?'; $stmt = $pdo->prepare($sql); if (strlen($keywords) > 0) { $stmt->bindValue(1, '%' . $keywords . '%', PDO::PARAM_STR); $stmt->bindValue(2, (int)$offset, PDO::PARAM_INT); $stmt->bindValue(3, (int)$pageSize, PDO::PARAM_INT); } else { $stmt->bindValue(1, (int)$offset, PDO::PARAM_INT); $stmt->bindValue(2, (int)$pageSize, PDO::PARAM_INT); } $stmt->execute(); $results = $stmt->fetchAll(PDO::FETCH_ASSOC); $data = [ 'code' => 1, 'msg' => 'ok', 'rows' => $results, 'total_records' => (int)$total, 'page_number' => (int)$pageNo, 'page_size' => (int)$pageSize, 'page_total' => (int)$maxPage, ]; } catch (PDOException $e) { $data = [ 'code' => 0, 'msg' => $e->getMessage(), 'rows' => [], 'total_records' => 0, 'page_number' => 0, 'page_size' => (int)$pageSize, 'page_total' => 0, ]; } header('Content-type: application/json'); echo json_encode($data);4、最后数据库格式 /* Navicat MySQL Data Transfer Source Server Version : 80012 Target Server Type : MYSQL Target Server Version : 80012 File Encoding : 65001 Date: 2020-01-14 16:22:49 */ SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for pic -- ---------------------------- DROP TABLE IF EXISTS `pic`; CREATE TABLE `pic` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `path` varchar(255) DEFAULT NULL, `mark` tinyint(3) DEFAULT NULL, `scale` varchar(255) DEFAULT NULL, `info` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=3 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of pic -- ---------------------------- INSERT INTO `pic` VALUES ('1', './uploads/5e1d788084cc5.jpg', '1', '800*600', '这是测试图片1'); INSERT INTO `pic` VALUES ('2', './uploads/5e1d789766591.jpg', '1',);
-
JS唤醒Windows10/11消息通知 在写一个应用的时候需要显示网页来的消息,为了让用户不会错过消息,所以希望使用JS调用win10的通知消息,调用方法如下: JavaScript图片 JS调用window.Notification() 1、在页面打开的时候查看浏览器是否支持Notification API,如果支持,则判断是否有权限通知,没有的话交由用户判断是否允许通知(JS代码): // 判断浏览器是否支持唤醒 if (window.Notification) { let popNotice = () => { if (!Notification.permission === 'granted') return const notification = new Notification('阿巴阿巴', { body: '提示提示提示' }) // 点击通知的回调函数 notification.onclick = function() { window.open('https://baidu.com') notification.close() } } /* 授权过通知 */ if (Notification.permission === 'granted') { popNotice() } else { /* 未授权,先询问授权 */ Notification.requestPermission(function(permission) { popNotice() }) } }2.将应用部署到服务器之后只有https协议的网页可以调用通知功能。 如果是Win10/11系统的话,可以直接将上面代码复制到F12控制台运行
-
网站SEO优化步骤超详细完整版教程 一、准备 1、心态 长时间,不断学习。学习建站、基础代码、SEO全过程、实际操作并成功。 2、价值与优势 流量=价值。SEO是获得客户的技能,通过引流产生价值。 ①客户更精准,客户是主动的; ②成本低、排名稳定、关键词有可扩展性。 3 、SEO工作 ①PC站优化:网站架构、页面关系、代码优化、链接推送等;WAP优化:继承PC站的优化成果,进行代码优化、移动适配; ②内容发布:管理原创内容、转载内容、用户内容的更新频率与数量; ③数据分析:关注收录量、收录率、展现量。 ④做日志分析,对服务器/网站进行监控,处理异常情况,跟进方案策略。 4 、SEO误区 ①排名上不去,不能立即见效;(SEO需要时间,需要内容支撑) ②排名波动。(搜索引擎本身是动态的,不一定是SEO的问题) 5、思路 用一个对搜索引擎友好的系统,持续发布优质的内容,推送给搜索引擎以满足搜索用户的需求。 (1)前期:较低的搜索引擎信任度,可操作范围广。此阶段重点集权,提升网站信任度; (2)中期:周期长的筑基期。需要更新文章、外链、友链,积攒资源(大量的词排名); (3)后期:需要分析海量数据,分析需求,做出规划。 SEO图片 二、建站 1、准备 域名 购买域名及套餐。常用com,cn,net。域名尽量贴近品牌,拼音或者英文,尽量不要用中文。合理使用老域名,规避被惩罚域名。 空间 存放网站的空间。可以买实体主机/租虚拟主机。注意主机稳定性,安全性。 程序 开源、自主开发/使用建站程序。选用建站程序时,要分析网站定位选择合适的建站程序。 FTP 向空间传送程序/文件的工具。 2、绑定空间与解析域名及备案 建立空间与域名的联系,国内网站要备案。(具体操作运营商都会提供,建议绑定之前把网站做好) 3、链接FTP 需要:主机地址,账号,密码,登录后可向空间上传内容。 /:FTP根目录,只可读取。 htdocs/:存放网站文件的地方。 htdocs/logreport/:访问统计报告存放目录,只可读取。 myfolder/:不会被web用户看到,存放临时不公开资源,站点备份、数据库备份等。 ftplogs/:ftp访问日志,只可读取。 wwwlogs/:www访问日志,只可读取。 backup/:系统自动生成的数据库备份位置,只可读取。 (不同运营商有些许不同,操作方式运营商会提供) 4、上传文件 上传压缩文件,注意解压缩需要在主机的管理系统里完成。 5、安装程序 准备数据库账号密码四个信息:地址、名称、账号、密码。访问域名,按照提示安装。(不同建站程序有些许不同,操作方式参考建站程序中的说明) 6、使用模板 将下载的模板放到templets,在程序后台使用模板。使用模板前要考虑网站的大小定位,模板有PC端、移动端、PC+移动端、响应式、H5等,根据各自特点进行选择。 7、注意的问题 首选域:尽量使用www,做好301,明确sitemap后进行推送; 301:一个自动跳转,将权重集中向首选域; URL规范:层次要少,分类页采用目录式,内容页采用内页式。分类与内容不要产生关联; 英文式:www.yukiyyy3.com/me/ 内容式:www.yukiyyy3.com/2022/02/13/bingdundun-2/ 目录式:www.yukiyyy3.com/2022/02/28/go/ 二级域名扁平式:xxx.xxx.com/xxx.html URL标准化:确保页面唯一指定URL; 面包屑导航:注意首选域和标准化,包含核心词; https:http的加密传输方式,需要安装SSL协议证书; MIP/AMP:移动加速器,需要通过HTML规范、JS运行环境、Cache缓存实现移动加速; Sitemap:网站地图方便搜索引擎抓取。TXT/XML式,按照更新时间倒叙排列。注意周更,放入txt文件中,之后提交给搜索引擎; txt:与搜索引擎的协议,生效时间一个月。注意文件不能为空,放入sitemap,屏蔽404页、结果页、后台、图片、下载文件等; Nofollow:不给链接分配权重,灵活使用; 定向锚文本:关键词带上链接,这个链接指向的页面主要优化的关键词和锚文本一样,不一样就是普通锚文本。这样会给目标页面权重,还告知了搜索引擎优化的关键词是什么; 三、算法规则 1、历史算法 网站的表现会被搜索引擎记录,存放在域名中。搜索引擎会更加信任老域名。一个有好历史数据的域名,无灰色行业记录、权重高、有备案。可以通过站长工具检测域名安全、权重、备案情况,购买老域名。 2、闪电算法 网站打开速度要快2s。在保持网站素材的质量的情况下,对素材进行压缩,规范样式。 购买或租用性能好的主机。 CDN加速,静态化页面,采用缓存懒加载,整合CSS,JS放页脚。 3、机械识别 (1)网站能被搜索引擎识别的内容:文字、图片、链接、html标签。Flash、js、css、iframe框架不能识别。 (2)网站的链接不要包含中文;减少链接带的参数;减少链接层次结构、长度。 (3)不要给网站设置权限,搜索引擎无法识别需要登录的网站。 (4)确保服务器稳定。网站无死链,安全不被黑。 4、主题/标题打造 分析网站定位确定主题。标题尽量相关、精简,核心词-品牌词、核心词_需求-品牌。 5、网站结构 确保网站层次结构精简,不跑题,需求解决度高。 6、点击算法 搜索引擎会记录用户的点击行为,分析用户体验。设计可点击的标题时要结合用户需求痛点,增加点击率。 7、描述写法 要研究需求,照应标题中的关键词,但不要堆砌关键词。 8、降权/惩罚 网站运营灰色内容,或者堆积关键词,优化作弊等。网站会降权,进入一个长期的考核过程。 9、优质内容 优秀的内容或者优秀的原创内容,浏览数据好,点击的次数,深度,时间更好。 10、时效性 搜索引擎为更好满足需求,统计大数据,关键词的搜索具有时效性。把握时效,抓住机遇。 11、匹配算法 搜索引擎计算标题与页面内容的相关度,内容质量、体验都有影响。 12、搜索引擎排名过程 网站上线-爬取网站-过滤计算-收录建立索引-计算得分-得出排名 算法就是分析数据,多维度分析数据。确保各个环节的质量,策略源于就能提高网站排名。 13、飓风算法 会对采集站进行降权,并删除内容。 专注于一个领域,加大原创内容比例,内容的从新排版,注意字体大小等,尽量减少伪原创工具的使用。内容要照顾用户需求。 14、细雨算法 针对B2B网站标题。标题不要带官网,联系方式,堆积关键词。 15、清风算法 标题内容不符,标题堆积关键词,下载站欺骗下载。 内容相符,不能欺骗下载,保证正常下载,不要加下载条件。 16、惊雷算法 针对点击快排,不要参与点击快排。针对黑链,群发外链、泛站、泛目录、群链。 平时关注自己的外链,不参与作弊。 17、绿萝算法 打击链接交易。 不参与交易,内容为王。 18、石榴算法 打击广告,打击弹窗。 优化广告投放方式,提高有效收录率。 19、蓝天算法 打击卖软文,卖目录网站。 四、关键词设置与挖掘 1 、TDK中的关键词(格式不是绝对的,要兼顾定位与转化) 标题写法T 出现在搜索结果中,影响排名。26个字符。(核心词-品牌词、核心词_需求-品牌、核心词_需求+延申-品牌词) 描述写法D 出现在搜索结果中,间接影响排名,60-78个字符。(包含标题中的词,使核心词出现两次以上。做什么、解决什么问题) 关键字设置K 3-5个英文,符号“,”隔开。(标题、描述中词的组合) 2、网站内容中的关键词 栏目 栏目名称-品牌词 文字/内容 文章标题-品牌词,在内容中布局关键词,提升内容与关键词的关联程度。 图片alt 图片的属性描述。一句话概括内容包含关键词或相关词,图片清晰度,大小,水印,文字都有影响。 H标签 H1必须唯一,作为页面参考的主题,放在代表页面的主题处。 3、长尾关键词挖掘 搜索引擎下拉框 在搜索引擎搜索框中输入关键词会出现相应的长尾关键词联想。可以通过空格、字符改变联想出的关键词。收集这些关键词,这些关键词的记录了搜索历史,而且实时预测能力好。 相关搜索 百度搜索结果页最下端会给出相关的关键词。周期更长,可能涉及用户未满足的需求。 百度指数 http://index.baidu.com通过其工具分析关键词图谱、相关词。 百度推广助手 要注册账号www2.baidu.com及下载客户端editor.baidu.com。工具提供更好的筛选功能,更好的统计数据,可以导入导出。 百度资源搜索平台 验证网站后,https://ziyuan.baidu.com/可以分析关键词的流量。有PC和移动端,30天左右数据导出。平台还提供百度的资源文档。 百度统计 多维度分析关键词,可以筛选条件。可以得到关键词指标和历史趋势。 5118平台/站长之家/爱站关键词/金花站长 各个搜索引擎选择;长尾关键词、相关词;PC端、移动端;挖掘同行网站。 总结 关键词挖掘步骤:核心关键词–长尾关键词–关键词分析–关键词选择–关键词布局 五、搜索引擎与网站 1、判断爬取 使用工具分析网站日志,得出爬取频次;看快照是否更新,页面是否收录。 2、过滤 互联网存在垃圾页面,无价值页面要过滤,以节省资源。页面质量低下会被搜索引擎过滤掉。搜索引擎从三大标签和页面中提取信息,计算相关度,不匹配的过滤。 3、收录与索引 (1)先收录后索引,是排名的基础。通过Site:+域名看收录(页面数X收录率),站长平台看索引量。 (2)无效收录,收录没有带来流量,被搜索引擎压箱底。内容高质量,有创新打破无效收录,同时提升数量增加收录数。 4、新站收录 主动提交给搜索引擎 发外链引流 5、稳定收录 保持规律更新; 保持内容质量; 网站最新的内容设立个模块; 已收录的页面锚文本向未收录页面; 主动推送; Sitemap及时更新; 未收录页面在首页展示; 站外引流; 学会分析日志。 6、不收录 网站被k没有收录就换域名; 内容不收录,检查原创度; 分析日志,看返回码; 安排更多权重; 7、排名下降 site网站; 关注外链; 链接抓取是否异常; 不符合百度算法。 内页排名不好,加强内容与链接; 考核期。 8、提高权重 权重是一种逻辑,不同平台逻辑不同,仅供参考; 做好首选域; URL标准化; 稳定内容更新 更新的内容做定向锚文本; 面包屑导航; 友情逻辑; 单向链接; 301传递权重。 六、内容质量 1、高质量内容评判 成本 内容耗费的资源与人力。 内容完整 完整的解决了需求,各种维度丰富内容以满足需求。 信息安全有效 发布的信息都要经过搜索引擎的内部审核,其他审核。通过搜索引擎的产品使得信任的提升。 2、伪原创 找到解决需求的高质量文章。标题使用关键词的同时创新语句结构,开头提出问题吸引用户,过程修改填词,结尾留下收益方式。 3、原创 搜索引擎鼓励原创,会增加网站评分。 4、外链 他人的网站有自己网站的链接。文章、发布平台以及链接。重点:收集平台。尝试积累可行的平台。看竞争对手的如何发外链。 友情链接(高质量外链),互相挂链接,避免交换惩罚和考核期的链接。优先考虑相关、年龄、收录、排名。40个左右,有规律的增加。 七、稳定排名 1、做好网站seo优化 网站结构是否清晰明确,满足用户体验与结构算法; 关键词动态平衡,关键词密度经常变动,满足时效算法; 站内元素优化,TDK、图片、文章优化; 站外第三方平台优化,发外链、友情链、发软文; 独特的网站结构,独立的IP,高质量的主机,保持高水准内容制作; 2、分析数据 关键词需求分析 使用关键词挖掘工具、站长平台、百度工具等分析用户需求。兼顾显性需求与隐性需求。把握常规数据(更新栏目),抓住非常数据(更新文章),排除非需求数据。 竞争对手数据分析 模仿竞争对手的优秀网站,交换友链。 行业需求分析 关注行业动态,抓住时效机遇。 分析做过的SEO数据 分析seo效果,找到不足,发现痛点。 通过需求数据修改栏目 保证栏目精简,小而全,同时兼顾用户体验与搜索引擎算法。 通过需求数据修改内容 一定要有对用户需求的引导。 3、影响因素 长时间的优化网站,解决用户需求;关注行业动态、分析数据,保持点击率。 (1)不稳定因素 网页打开速度不稳定,存在404,服务器响应慢都会增加跳出率,影响排名。缺乏对用户的引导,需求不对口,增加跳出率,影响排名。 (2)没排名因素 基础优化不到位、被处罚、收录数低、网站品牌不相关、内容质量差等。 八、全网营销 1、怎样全网营销 建设好自身网站的情况下,坚持全网平台发布软文,留下外链、建立友链。 2、打造品牌故事 网站展示页、标签、编辑更新围绕产品,品牌优化。到第三方平台发布软信息,之后附带产品品牌。 3、扩展投放渠道 精准截留,借助他人平台。每个产品通过视频、文章、图片进行曝光。 4、引流 通过外链引来流量,全平台都可以发外链:B2B、导航网站、招聘网站、第三方平台、论坛、聊天工具。不做无效链接,同时有规律的增加友链。 九、其他 1、栏目页优化 产品名称包含核心词; 图片alt包含核心词; 页面下方添加链接; 做好分类; 站内锚文本定向给栏目页; 做好栏目页TDK; 链接格式:xxx.com/x/id。 2、产品页面优化 做好TDK,重点围绕产品属性。产品名称+搜索词+属性+延申词; 链接:xxx.com/product/id.html,产品链接不要与分类栏目关联。大型网站可以使用二级域名,扁平化处理; 图文并茂; 多个模块介绍详情,简介,属性,展示,案例,问题等; 推荐相关产品,添加锚文本。 3、文章页面优化 链接:xxx.com/news/id.html,大型网站使用二级域名; TDK;文章名称+延申词; 图文并茂; 文章内容重现TDK内容; 保持原创度; 相关文章推荐,定向锚文本; 内容多维,是什么,为什么,有什么优势,问题,注意事项。 4、TAG标签优化 链接:xxx.com/tag/id; TDK围绕核心词延申,多个词组合; TAG在页面内多次出现,添加一个描述。 5、专题页面优化 与栏目是不同的,需要围绕个需求点,多维度优化。 链接:目录式/内容式; TDK:围绕主题进行延申,多个需求词组合。 6、筛选搜索页面优化 链接:多目录组合/条件词-条件词。。。; TDK:条件词组合+延申; 核心词多出现。 7 、SEO编辑与新媒体 新媒体注重时效:打开、留言、转发。SEO编辑注重长期:收录、排名、点击、停留。 SEO是个资料库,不要蹭热度,标题党。挖掘搜索词,做好需求,兼顾用户体验。 定类别-查资料-挖词-编辑发布-提交搜索引擎-做关键词-时刻分析反馈情况-做出调整 SEO是产品运营的核心手段,每一个网站皆可成为知名品牌,获得破千流量,SEO可以解决排名流量转化率品牌口碑信用度、用户回头率等若干问题!
-
Js自动播放HTML音乐(不受浏览器限制,无需先与浏览器交互,无需对浏览器进行修改) 众所周知,声音无法自动播放一直是 IOS/Android 上的惯例。桌面版 Safari 也在 2017 年第 11 版宣布禁止带声音的多媒体自动播放功能。随后 2018 年 4 月发布的 Chrome 66 正式关闭了声音的自动播放,这意味着音频自动播放和视频自动播放在桌面浏览器中也会失效。 JavaScript图片 而通过网上搜索来解决这个问题,大部分都会提到使用 javascript 原生的 play()来解决。但是,当你运行它的时候,你会发现你在 Chrome 浏览器下调用 play 后的错误: DOMException: play() failed because the user didn’t interact with the document first. 但是,如果你想的是将音频当作背景音乐来播放时,当页面加载时音频文件就会自动响起,这个时候,用户是没有与页面进行数据交互的,所以 play()会报错,很多人百度后便会找到两种主流的方法 One: 1. 进入到 chrome://flags/#autoplay-policy 2. 找到Autoplay policy选项,设置为Setting No user gesture is required 3. 重启:Relaunch Chrome Two: 1. 直接在video标签中属性muted属性,静音播放即可首先说一下方法一。当前的谷歌浏览器已经删除了自动播放策略选项,所以当你进入谷歌浏览器进行设置时,是找不到这个选项的。而且作为网页的背景音乐,你还要把效果展示给别人看。所以,改变浏览器选项还不够成熟。先说第二种方法。如果作为背景音乐播放,可以更改静音属性,达到自动播放的效果。自动播放是可以的,但是这里用户需要的是背景音乐,而且是音频文件,静音属性无法达到这个效果。然后有人问,既然谷歌 Chrome 的背景音乐不能自动播放,究竟怎么解决呢? 这里使用 Audio API 的 AudioContext 来自于我搭建的一个播放器。 //浏览器适用 contextClass = window.AudioContext = window.AudioContext || window.webkitAudioContext || window.mozAudioContext || window.msAudioContext; try { var context = new contextClass(); var source = null; var audioBuffer = null; function stopSound() { if (source) { source.stop(musics); //立即停止 } } function playSound() { source = context.createBufferSource(); source.buffer = audioBuffer; source.loop = true; source.connect(context.destination); source.start(0); //立即播放 } function initSound(arrayBuffer) { context.decodeAudioData(arrayBuffer, function(buffer) { //解码成功时的回调函数 audioBuffer = buffer; playSound(); }, function(e) { //解码出错时的回调函数 console.log('404', e); }); } function loadAudioFile(url) { var xhr = new XMLHttpRequest(); //通过XHR下载音频文件 xhr.open('GET', url, true); xhr.responseType = 'arraybuffer'; xhr.onload = function(e) { //下载完成 initSound(this.response); }; xhr.send(); } //这里用来存储背景音乐的路径 loadAudioFile('audio/music.flac'); } catch (e) { console.log('无法找到音乐!'); }构建播放器后,可以在进入页面时缓存,然后自动播放背景音乐,不考虑浏览器。 注意事项 这种方法只对浏览器有效,无法实现 APP 上自动播放音乐的效果。 API 的 AudioContext 可能用的不多,欢迎大牛和有个人见解的人站出来和我们讨论。
-
PHP使用Curl函数进行远程请求案例,爬虫,可保存账户登录状态 CURL简介: CURL可以使用URL的语法模拟浏览器来传输数据,因为它是模拟浏览器,因此它同样支持多种协议,FTP, FTPS, HTTP, HTTPS, GOPHER, TELNET, DICT, FILE 以及 LDAP等协议都可以很好的支持,包括一些:HTTPS认证,HTTP POST方法,HTTP PUT方法,FTP上传,keyberos认证,HTTP上传,代理服务器,cookies,用户名/密码认证,下载文件断点续传,上传文件断点续传,http代理服务器管道,甚至它还支持IPv6,scoket5代理服务器,通过http代理服务器上传文件到FTP服务器等等。 本文主要介绍的是php远程请求CURL(爬虫、保存登录状态)的相关内容,下面话不多说了,来一起看看详细的介绍吧 php图片 GET案例: <?php /** * curl_get * @param $url * @param null $param * @param null $options * @return array */ function curl_get($url, $param = null, $options = null) { if (empty($options)) { $options = array( 'timeout' => 30, // 请求超时 'header' => array(), // 数据格式如array('Accept: */*','Accept-Encoding: gzip, deflate, br') 'cookie' => '', // cookie字符串,浏览器直接复制即可 'cookie_file' => '', // 文件路径,并要有读写权限的 'ssl' => 0, // 是否检查https协议 'referer' => null ); } else { empty($options['timeout']) && $options['timeout'] = 30; empty($options['ssl']) && $options['ssl'] = 0; } $result = array( 'code' => 0, 'msg' => 'success', 'body' => '' ); if (is_array($param)) { $param = http_build_query($param); } $url = strstr($url, '?') ? trim($url, '&') . '&' . $param : $url . '?' . $param; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); // 设置url !empty($options['header']) && curl_setopt($ch, CURLOPT_HTTPHEADER, $options['header']); // 设置请求头 if (!empty($options['cookie_file']) && file_exists($options['cookie_file'])) { curl_setopt($ch, CURLOPT_COOKIEFILE, $options['cookie_file']); curl_setopt($ch, CURLOPT_COOKIEJAR, $options['cookie_file']); } else if (!empty($options['cookie'])) { curl_setopt($ch, CURLOPT_COOKIE, $options['cookie']); } curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); //curl解压gzip页面内容 curl_setopt($ch, CURLOPT_HEADER, 1); // 获取请求头 curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // 输出转移,不输出页面 !$options['ssl'] && curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, $options['ssl']); // 禁止服务器端的验证ssl !empty($options['referer']) && curl_setopt($ch, CURLOPT_REFERER, $options['referer']); //伪装请求来源,绕过防盗 curl_setopt($ch, CURLOPT_TIMEOUT, $options['timeout']); //执行并获取内容 $output = curl_exec($ch); $header_size = curl_getinfo($ch, CURLINFO_HEADER_SIZE); $header = substr($output, 0, $header_size); $output = substr($output, $header_size); //对获取到的内容进行操作 if ($output === FALSE) { $result['code'] = 1; // 错误 $result['msg'] = "CURL Error:" . curl_error($ch); } $result['header'] = $header; $result['body'] = $output; //释放curl句柄 curl_close($ch); return $result; } ?>POST案例: <?php /** * curl_post * @param $url 请求地址 * @param null $param post参数 * @param array $options 配置参数 * @return array */ function curl_post($url, $param = null, $options = array()) { if (empty($options)) { $options = array( 'timeout' => 30, 'header' => array(), 'cookie' => '', 'cookie_file' => '', 'ssl' => 0, 'referer' => null ); } else { empty($options['timeout']) && $options['timeout'] = 30; empty($options['ssl']) && $options['ssl'] = 0; } $result = array( 'code' => 0, 'msg' => 'success', 'body' => '' ); if (is_array($param)) { $param = http_build_query($param); } $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); // 设置url !empty($options['header']) && curl_setopt($ch, CURLOPT_HTTPHEADER, $options['header']); // 设置请求头 if (!empty($options['cookie_file']) && file_exists($options['cookie_file'])) { curl_setopt($ch, CURLOPT_COOKIEFILE, $options['cookie_file']); curl_setopt($ch, CURLOPT_COOKIEJAR, $options['cookie_file']); } else if (!empty($options['cookie'])) { curl_setopt($ch, CURLOPT_COOKIE, $options['cookie']); } curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); //curl解压gzip页面内容 curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $param); curl_setopt($ch, CURLOPT_HEADER, 1); // 获取请求头 curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // 输出转移,不输出页面 !$options['ssl'] && curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, $options['ssl']); // 禁止服务器端的验证ssl !empty($options['referer']) && curl_setopt($ch, CURLOPT_REFERER, $options['referer']); //伪装请求来源,绕过防盗 curl_setopt($ch, CURLOPT_TIMEOUT, $options['timeout']); //执行并获取内容 $output = curl_exec($ch); $header_size = curl_getinfo($ch, CURLINFO_HEADER_SIZE); $header = substr($output, 0, $header_size); $output = substr($output, $header_size); //对获取到的内容进行操作 if ($output === FALSE) { $result['code'] = 1; // 错误 $result['msg'] = "CURL Error:" . curl_error($ch); } $result['header'] = $header; $result['body'] = $output; //释放curl句柄 curl_close($ch); return $result; } ?>关于php远程请求CURL(爬虫,保存登录状态)的这篇文章到此结束。 其他请求类型行请参考这篇文章:PHP进行各种网络请求的方式和实现函数总结
-
PHP进行各种网络请求的方式和实现函数总结 首先,分析 php 发送网络请求的方法 对于 php 发送网络请求,我们最常用的请求是 curl。有时候我们也会使用 file_get_contents 函数来发送网络请求,但是 file_get_contents 只能完成一些间接的网络请求,稍微复杂一点的是无法完成的,比如文件上传、cookies、验证、表单提交等。php 中的 Curl 可以使用 url 的语法来模拟浏览器传输数据。因为是模拟浏览器,所以也支持多种协议。FTP,FTPS,http,httpS,Gopher,Telnet,Dict,File,LDAP 都可以很好的支持,包括一些:HTTPS 认证,HTTP POST 方法,Put 方法,FTP 上传,keyberos 认证,HTTP 上传,代理服务器,cookies,用户名/密码认证,下载文件断点续传,上传文件断点续传,HTTP 代理服务器管道,甚至它支持 IPv6,scoket5 代理服务器,通过 HTTP 代理服务器上传文件到 FTP 服务器等。,所以我们在开发中尽量使用 curl 做网络请求,不管是简单的还是复杂的。 图片 二、file_get_contents 发送网络请求示例 file_get_contents(path,include_path,context,start,max_length);参数描述path必需。规定要读取的文件。include_path可选。如果也想在 include_path 中搜寻文件的话,可以将该参数设为 "1"。context可选。规定文件句柄的环境。context 是一套可以修改流的行为的选项。若使用 null,则忽略。start可选。规定在文件中开始读取的位置。该参数是 PHP 5.1 新加的。max_length可选。规定读取的字节数。该参数是 PHP 5.1 新加的。一般用 file_get_contents 或者 fopen, file , readfile 等函数读取 url 的时候 会创建一个$http_response_header 变量保存 HTTP 响应的报头,使用 fopen 等函数打开的数据流信息可以用 stream_get_meta_data 获取 $html = file_get_contents('http://www.baidu.com'); print_r($http_response_header); $fp = fopen('http://www.baidu.com', 'r'); print_r(stream_get_meta_data($fp)); fclose($fp);摸拟 post 请求: $url = 'http://192.168.1.1/test.php'; $data = array( 'keyword' => 'test data', ); $content = http_build_query($data); $content_length = strlen($content); $options = array( 'http' => array( 'method' => 'POST', 'header' => "Content-type: application/x-www-form-urlencoded\r\n" . "Content-length: $content_length\r\n", 'content' => $content ) ); echo file_get_contents($url, false, stream_context_create($options));三、PHP 通过 curl 方法发送网络请求 curl 可以支持 https 认证、http post、ftp 上传、代理、cookies、简单口令认证等等功能,使用前需要先在你的 PHP 环境中安装和启用 curl 模块,这里有两种写法供大家参考: <?php function geturl($url){ $headerArray =array("Content-type:application/json;","Accept:application/json"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch,CURLOPT_HTTPHEADER,$headerArray); $output = curl_exec($ch); curl_close($ch); $output = json_decode($output,true); return $output; } function posturl($url,$data){ $data = json_encode($data); $headerArray =array("Content-type:application/json;charset='utf-8'","Accept:application/json"); $curl = curl_init(); curl_setopt($curl, CURLOPT_URL, $url); curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE); curl_setopt($curl, CURLOPT_SSL_VERIFYHOST,FALSE); curl_setopt($curl, CURLOPT_POST, 1); curl_setopt($curl, CURLOPT_POSTFIELDS, $data); curl_setopt($curl,CURLOPT_HTTPHEADER,$headerArray); curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); $output = curl_exec($curl); curl_close($curl); return json_decode($output,true); } function puturl($url,$data){ $data = json_encode($data); $ch = curl_init(); //初始化CURL句柄 curl_setopt($ch, CURLOPT_URL, $url); //设置请求的URL curl_setopt ($ch, CURLOPT_HTTPHEADER, array('Content-type:application/json')); curl_setopt($ch, CURLOPT_RETURNTRANSFER,1); //设为TRUE把curl_exec()结果转化为字串,而不是直接输出 curl_setopt($ch, CURLOPT_CUSTOMREQUEST,"PUT"); //设置请求方式 curl_setopt($ch, CURLOPT_POSTFIELDS, $data);//设置提交的字符串 $output = curl_exec($ch); curl_close($ch); return json_decode($output,true); } function delurl($url,$data){ $data = json_encode($data); $ch = curl_init(); curl_setopt ($ch,CURLOPT_URL,$put_url); curl_setopt ($ch, CURLOPT_HTTPHEADER, array('Content-type:application/json')); curl_setopt ($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt ($ch, CURLOPT_CUSTOMREQUEST, "DELETE"); curl_setopt($ch, CURLOPT_POSTFIELDS,$data); $output = curl_exec($ch); curl_close($ch); $output = json_decode($output,true); } function patchurl($url,$data){ $data = json_encode($data); $ch = curl_init(); curl_setopt ($ch,CURLOPT_URL,$url); curl_setopt ($ch, CURLOPT_HTTPHEADER, array('Content-type:application/json')); curl_setopt ($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt ($ch, CURLOPT_CUSTOMREQUEST, "PATCH"); curl_setopt($ch, CURLOPT_POSTFIELDS,$data); //20170611修改接口,用/id的方式传递,直接写在url中了 $output = curl_exec($ch); curl_close($ch); $output = json_decode($output); return $output; } ?>一个函数片时各种请求: function sendCurl($url, $data = null,$method='POST') { $method=strtoupper($method); $start_wdmcurl_time = microtime(true); $header = array(' application/x-www-form-urlencoded'); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_FAILONERROR, false); // https 请求 if (strlen($url) > 5 && strtolower(substr($url, 0, 5)) == "https") { curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); } if($method=='GET'){ if($data && is_array($data) && count($data)>0 ){ $url.="?".http_build_query($data); } curl_setopt($ch, CURLOPT_URL, $url); }elseif($method=='POST'){ curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $data); if (is_array($data) && count($data)>0) { curl_setopt($ch, CURLOPT_POST, true); $isPostMultipart = false; foreach ($data as $k => $v) { if ('@' == substr($v, 0, 1)) { $isPostMultipart = true; break; } } unset($k, $v); if ($isPostMultipart) { curl_setopt($ch, CURLOPT_POSTFIELDS, $data); } else { curl_setopt($ch, CURLOPT_POSTFIELDS, http_build_query($data)); } } }elseif(in_array($method,['PUT','DELETE','PATCH'])){ curl_setopt($ch, CURLOPT_CUSTOMREQUEST,$method); curl_setopt($ch, CURLOPT_POSTFIELDS, $data); } curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch,CURLOPT_HTTPHEADER,$header); $reponse = curl_exec($ch); curl_close($ch); return $reponse; }四、使用 PHP Composer 的扩展库 guzzlehttp composer require guzzlehttp/guzzle$client = new \GuzzleHttp\Client(); $response = $client->request('GET', 'https://api.github.com/repos/guzzle/guzzle'); echo $response->getStatusCode(); // 200 echo $response->getHeaderLine('content-type'); // 'application/json; charset=utf8' echo $response->getBody(); // '{"id": 1420053, "name": "guzzle", ...}' // Send an asynchronous request. $request = new \GuzzleHttp\Psr7\Request('GET', 'http://httpbin.org'); $promise = $client->sendAsync($request)->then(function ($response) { echo 'I completed! ' . $response->getBody(); }); $promise->wait();平常开发中尽量使用方法三,自定义 curl 处理网络请求,或者 composer 的 guzzlehttp 扩展库,用起来也很方便。
-
什么样的网站内容是优质内容? 前言 网站搭建好之后,接下来就是不断更新网站内容。建设网站是网站的身体,网站的内容是网站的灵魂。一个网站的内容直接决定了网站的成败。 收集一百篇一模一样的文章,搜索引擎不喜欢,用户也不喜欢。这样的网站毫无意义。 那么什么样的文章才是质量高的好文章呢?有什么标准吗?搜索引擎也不会给出100%的标准,但是我们可以试试下面的方法,可以大大提高文章质量。 SEO图片 能否满足用户需求 发布的文章是用户需要的,能满足用户需求的吗?比如用户搜索一篇文章:如何发布一个高质量的网站,你的内容写的千篇一律,自吹自擂,毫无价值。谁来读? 只要能满足用户需求,即使是伪原创的文章也可以纳入排名。 和网站内容相关吗? 发布的内容要和网站的主题相关,这一点在搜索引擎算法中也有提及。IT网站发布烹饪内容,不仅用户不会看,搜索引擎还会扣分,不要乱发文章。 是否符合用户体验 站点内容的用户体验就是排版,排版要标准化。怎么能称之为标准化?你可以通过看别人出版社怎么排版来给书排版。 标题要清晰,主要内容要突出,段落要有明显的间距。简而言之,用户应该一目了然。
-
CC攻击介绍 关于 CC 攻击(ChallengeCoHapsar,挑战黑洞) CC 攻击是 DDOS 攻击的一种常见类型,攻击者借助代理服务器生成指向受害主机的合法请求,实现 DDOS 和伪装。CC 攻击是一种针对 Http 业务的攻击手段,该攻击模式不需要太大的攻击流量,它是对服务端业务处理瓶颈的精确打击。 图片 攻击目标 大量数据运算、数据库访问、大内存文件等,攻击者控制某些主机不停地发大量数据包给对方服务器造成服务器资源耗尽,一直到岩机崩溃。 最简单的理解,3000 台电脑同时访问你的网站开三个浏览器按住 F5 是一种什么样的体验,有点特点的,死循环请求搜索接口,批量访问大文件等等!比如这个 URL 就是一个搜索接口,我测试的时候还没有做频率限制,和分页限制,100 并发压测直接就凉了,随后直接加上了频率限制! 特征 被攻击服务器,一瞬间会带宽飙升,随后 CPU,内存,io,随着飙升! 特点 就是攻击方式简单,隐藏性高,量大! 缺点 需要持续压制直至攻击服务器岩机,如果在中途停止了压测,一般情况下服务器很快就能恢复,或者宕机服务自动重启,恢复业务正常运行!