找到
28
篇与
6v6博客
相关的结果
- 第 3 页
-
 在 Typecho 中实现通过输入“#标签”自动填充标签功能 在 Typecho 中使用 Joe 编辑器时,实现通过输入“#标签”自动填充标签功能,可以通过以下几种方法实现: 方法一:使用 AutoTags 插件 AutoTags 是一款专为 Typecho 设计的开源插件,能够自动提取文章中的关键词并生成标签。虽然它不是直接通过“#标签”来实现自动填充,但它可以根据文章内容智能生成相关标签,非常实用。 安装步骤: 1. 克隆仓库:通过 Git 将 AutoTags 项目下载到你的 Typecho 插件目录下: git clone https://github.com/DT27/AutoTags.git2. 启用插件:登录你的 Typecho 管理后台,进入“控制台”->“插件”,找到名为“AutoTags”的插件并点击启用。 3. 配置插件(可选):进入插件设置页面调整默认生成标签的数量等选项。 方法二:使用 TagSelector 插件 TagSelector 是一款增强后台标签功能的插件,支持标签展示和选择。虽然它不能直接实现通过“#标签”自动填充,但它可以让你在后台编辑文章时更方便地选择已有的标签。 安装步骤: 下载插件:从 Typecho 插件库下载 TagSelector 插件。 上传插件:将下载的插件文件夹 TagSelector 上传到 Typecho 的插件目录(usr/plugins/)。 启用插件:在 Typecho 后台插件管理页面启用 TagSelector 插件。 方法三:自定义代码实现 如果你希望直接通过输入“#标签”来实现自动填充,可以通过自定义代码的方式实现。以下是一个简单的实现方法: 实现步骤: 1. 编辑主题文件:在你的主题文件夹中找到 functions.php 文件,如果没有则创建一个。 2. 添加代码:在 functions.php 文件中添加以下代码: function autoTags($content) { preg_match_all('/#(\w+)/', $content, $matches); $tags = array_unique($matches[1]); return implode(',', $tags); }3. 修改文章发布逻辑:在 admin/write-post.php 文件中找到标签输入框的代码: <p><input id="tags" name="tags" type="text" value="<?php $post->tags(',', false); ?>" class="w-100 text" /></p>在其下方添加以下代码: <script> document.getElementById('text').addEventListener('input', function() { var content = this.value; var xhr = new XMLHttpRequest(); xhr.open('POST', '<?php echo Typecho_Common::url('action/write-post.php', Typecho_Common::getOptions()->index); ?>', true); xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded'); xhr.send('do=autoTags&content=' + encodeURIComponent(content)); xhr.onload = function() { if (xhr.status === 200) { document.getElementById('tags').value = xhr.responseText; } }; }); </script>4. 处理自动标签逻辑:在 admin/write-post.php 文件中找到 do=autoTags 的处理逻辑,添加以下代码: if (isset($_POST['do']) && $_POST['do'] == 'autoTags') { header('Content-Type: text/plain'); echo autoTags($_POST['content']); exit; }博客:6v6.ren 通过以上方法,你可以实现通过输入“#标签”自动填充标签的功能,提升你的写作体验。
在 Typecho 中实现通过输入“#标签”自动填充标签功能 在 Typecho 中使用 Joe 编辑器时,实现通过输入“#标签”自动填充标签功能,可以通过以下几种方法实现: 方法一:使用 AutoTags 插件 AutoTags 是一款专为 Typecho 设计的开源插件,能够自动提取文章中的关键词并生成标签。虽然它不是直接通过“#标签”来实现自动填充,但它可以根据文章内容智能生成相关标签,非常实用。 安装步骤: 1. 克隆仓库:通过 Git 将 AutoTags 项目下载到你的 Typecho 插件目录下: git clone https://github.com/DT27/AutoTags.git2. 启用插件:登录你的 Typecho 管理后台,进入“控制台”->“插件”,找到名为“AutoTags”的插件并点击启用。 3. 配置插件(可选):进入插件设置页面调整默认生成标签的数量等选项。 方法二:使用 TagSelector 插件 TagSelector 是一款增强后台标签功能的插件,支持标签展示和选择。虽然它不能直接实现通过“#标签”自动填充,但它可以让你在后台编辑文章时更方便地选择已有的标签。 安装步骤: 下载插件:从 Typecho 插件库下载 TagSelector 插件。 上传插件:将下载的插件文件夹 TagSelector 上传到 Typecho 的插件目录(usr/plugins/)。 启用插件:在 Typecho 后台插件管理页面启用 TagSelector 插件。 方法三:自定义代码实现 如果你希望直接通过输入“#标签”来实现自动填充,可以通过自定义代码的方式实现。以下是一个简单的实现方法: 实现步骤: 1. 编辑主题文件:在你的主题文件夹中找到 functions.php 文件,如果没有则创建一个。 2. 添加代码:在 functions.php 文件中添加以下代码: function autoTags($content) { preg_match_all('/#(\w+)/', $content, $matches); $tags = array_unique($matches[1]); return implode(',', $tags); }3. 修改文章发布逻辑:在 admin/write-post.php 文件中找到标签输入框的代码: <p><input id="tags" name="tags" type="text" value="<?php $post->tags(',', false); ?>" class="w-100 text" /></p>在其下方添加以下代码: <script> document.getElementById('text').addEventListener('input', function() { var content = this.value; var xhr = new XMLHttpRequest(); xhr.open('POST', '<?php echo Typecho_Common::url('action/write-post.php', Typecho_Common::getOptions()->index); ?>', true); xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded'); xhr.send('do=autoTags&content=' + encodeURIComponent(content)); xhr.onload = function() { if (xhr.status === 200) { document.getElementById('tags').value = xhr.responseText; } }; }); </script>4. 处理自动标签逻辑:在 admin/write-post.php 文件中找到 do=autoTags 的处理逻辑,添加以下代码: if (isset($_POST['do']) && $_POST['do'] == 'autoTags') { header('Content-Type: text/plain'); echo autoTags($_POST['content']); exit; }博客:6v6.ren 通过以上方法,你可以实现通过输入“#标签”自动填充标签的功能,提升你的写作体验。
-
Typecho 博客快速收录秘籍:IndexNow 自动提交插件大揭秘 Typecho 博客快速收录秘籍:IndexNow 自动提交插件大揭秘 在互联网的世界里,内容的快速曝光是每个博主的梦想。尤其是对于使用 Typecho 搭建博客的朋友们来说,如何让新发布的文章迅速被搜索引擎收录,是一个至关重要的问题。今天,就让我们一起探索如何通过 IndexNow 自动提交插件,让 Bing 搜索引擎快速收录你的 Typecho 博客文章。 一、什么是 IndexNow? IndexNow 是一个由 Bing、Yandex 和其他搜索引擎共同推出的协议,旨在帮助网站快速将新内容提交给搜索引擎,从而加速内容的收录。简单来说,IndexNow 就像是一个“快递服务”,能够将你的文章快速送到搜索引擎的“家门口”,让搜索引擎更快地发现和收录你的内容。 二、为什么选择 Bing 的 IndexNow? 虽然 Google 是目前最主流的搜索引擎,但 Bing 也在不断努力提升自己的搜索体验。而且,Bing 的 IndexNow 功能相对简单易用,尤其是对于小型博客和独立站来说,是一个非常实用的选择。此外,Bing 站长平台提供了丰富的工具和数据,可以帮助你更好地了解网站的收录情况和优化方向。 三、Typecho 的 IndexNow 自动提交插件 目前,Typecho 社区已经开发了几款可以实现 IndexNow 自动提交功能的插件。这些插件能够让你在发布新文章时,自动将文章的 URL 提交给 Bing 的 IndexNow 接口,从而加速文章的收录。接下来,我们将详细介绍两款常用的插件。 (一)PostToBingIndexNow 插件 1. 插件简介 PostToBingIndexNow 是一款专门为 Typecho 设计的插件,能够自动将新发布的文章 URL 提交到 Bing 的 IndexNow 接口。它简单易用,适合大多数 Typecho 用户。 2. 使用方法 下载插件:从 GitHub 下载插件文件。 上传插件:将下载的文件上传到你的 Typecho 网站的 /usr/plugins 目录下,并解压,重命名为 PostToBingIndexNow。 启用插件:登录到 Typecho 后台,进入插件管理页面,启用 PostToBingIndexNow 插件。 配置插件:在网站根目录下创建一个 temp_log 文件夹,用于存放日志文件。然后,在 Bing 站长平台申请一个 IndexNow 的 API Key。将申请到的 Key 填写到插件的设置页面中,并保存设置。最后,将 Bing 提供的 key.txt 文件上传到网站根目录。 测试是否生效:发布一篇新文章后,查看 temp_log 文件夹下的 push_bing.log 文件,确认是否成功提交。也可以在 Bing 站长平台的 IndexNow 页面查看推送记录。 (二)BingIndexNow 插件 1. 插件简介 BingIndexNow 插件同样可以实现将 Typecho 网站的文章自动提交到 Bing 的 IndexNow 接口。它的操作相对简单,适合新手用户。 2. 使用方法 下载插件:插件下载地址:蓝奏云网盘。 上传插件:下载后将插件上传到 /usr/plugins 目录,并重命名为 BingIndexNow。 启用插件:在 Typecho 后台的插件管理页面启用 BingIndexNow 插件。 配置插件:在 Bing 站长平台申请一个 IndexNow 的 API Key。将申请到的 Key 填写到插件设置页面中。插件会自动创建验证文件,无需手动上传。 测试是否生效:发布新文章后,查看插件目录下的 log.txt 文件,确认是否成功提交。 四、使用 IndexNow 插件的注意事项 API Key 的申请:在 Bing 站长平台申请 IndexNow 的 API Key 时,需要按照平台的指引完成相关步骤,包括下载并上传验证文件。 日志文件:插件的日志文件可以帮助你确认提交是否成功。如果返回的状态码不是 200,请根据 Bing 站长平台的说明进行调整。 网站内容质量:虽然 IndexNow 可以加速文章的收录,但最终是否被收录以及排名如何,仍然取决于网站内容的质量。 五、总结 通过使用 IndexNow 自动提交插件,你可以轻松实现 Typecho 网站文章的自动提交功能,加速文章被 Bing 搜索引擎收录。无论是 PostToBingIndexNow 还是 BingIndexNow 插件,都提供了简单易用的配置方法和强大的功能,帮助你的博客内容更快地出现在搜索引擎的结果页面上。 如果你还在为如何让文章快速被收录而烦恼,不妨试试这些插件吧!它们就像你博客的“加速器”,让你的内容能够更快地被搜索引擎发现。 更多资源在博客 6v6.ren
-
解决 Windows 10 中“显示无效开关 - 'force'”的问题 在使用 Windows 10 时,如果尝试通过命令行运行 gpupdate /force 来强制更新组策略,但系统提示“显示无效开关 - 'force'”,这可能是由多种原因导致的。以下是一些可能的原因及解决方法,帮助你快速解决问题。 一、检查命令格式 首先,确保你在命令提示符中输入的命令格式完全正确。正确的命令格式为: gpupdate /force 如果输入了多余的空格、符号或大小写错误,可能会导致“无效开关”的错误提示。建议仔细检查并重新输入命令。 二、确认系统版本支持组策略功能 Windows 10 家庭版默认不支持组策略编辑器(gpedit.msc)和相关命令,因此无法使用 gpupdate 命令。如果你使用的是 Windows 10 家庭版,可以通过以下方法启用组策略功能: 启用组策略功能的步骤 创建批处理文件: 打开记事本,将以下代码复制到其中: @echo offpushd "%~dp0"dir /b %systemroot%\Windows\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientExtensions-Package~3*.mum >gp.txtdir /b %systemroot%\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientTools-Package~3*.mum >>gp.txtfor /f %%i in ('findstr /i . gp.txt 2^>nul') do dism /online /norestart /add-package:"%systemroot%\servicing\Packages\%%i"pause将该文件保存为 .bat 文件,例如命名为 enable_gpedit.bat。 运行批处理文件: 右键单击保存的 .bat 文件,选择“以管理员身份运行”。运行过程中可能会提示安装相关功能,完成后即可启用组策略功能。 三、检查网络连接和域控制器 如果你的计算机连接到域,但网络连接不稳定或无法访问域控制器,可能会导致 gpupdate /force 命令失败。你可以通过以下步骤检查和修复: 检查网络连接 打开命令提示符(以管理员身份),输入以下命令检查与域控制器的连接: ping -n 4 <域控制器IP地址> 如果无法连接,检查网络设置或联系网络管理员。 确保 DNS 设置正确。在命令提示符中输入以下命令:ipconfig /all 查看 DNS 服务器地址是否正确。 四、以管理员身份运行命令提示符 确保你以管理员身份运行命令提示符。右键点击“开始”按钮,选择“命令提示符(管理员)”,然后再次运行 gpupdate /force 命令。 五、删除组策略配置文件 如果上述方法仍然无法解决问题,可以尝试删除组策略配置文件,然后重新启动计算机。具体步骤如下: 打开命令提示符(以管理员身份),输入以下命令删除组策略配置文件: RD /S /Q "%WinDir%\System32\GroupPolicyUsers" RD /S /Q "%WinDir%\System32\GroupPolicy" 重启计算机,让系统重新生成组策略配置文件。 六、其他建议 如果问题仍然存在,建议进一步检查系统设置或联系技术支持。以下是一些可能的替代方法: 检查系统激活状态:未激活的系统可能会导致某些功能受限。尝试重新激活 Windows。 更新系统:确保系统已更新到最新版本,有时系统更新可以修复此类问题。 创建新用户账户:有时系统账户可能存在问题。尝试创建一个新的用户账户,看是否在新账户下问题仍然出现。
-
如何在 Telegram 网页版中实现图片上传并自动生成图床链接 如何在 Telegram 网页版中实现图片上传并自动生成图床链接 原网站地址:6v6.ren 在使用 Telegram 网页版时,你可能需要将图片上传到图床并获取链接,以便在其他地方使用。虽然 Telegram 网页版本身没有直接支持这一功能,但通过一些第三方工具和服务,你可以轻松实现这一需求。以下是几种可行的解决方案: 1. 使用基于 Cloudflare Pages 和 Telegram 的图床工具 项目地址 CloudFlare-ImgBed 功能特点 支持图片、视频、动图等多种文件格式。 支持批量上传和实时上传进度显示。 上传完成后可直接复制 Markdown、HTML 等格式的链接。 支持自定义压缩质量和身份认证。 使用方法 部署 Cloudflare Pages: 在 GitHub 上克隆CloudFlare-ImgBed项目。 配置config.json文件,填写 Telegram Bot Token 和 Channel ID。 使用 Cloudflare Pages 部署项目。 上传图片: 打开部署好的图床工具页面。 将图片拖入上传区域或点击上传按钮选择图片。 上传完成后,复制生成的 Markdown 或 HTML 链接。 2. 使用 Telegram Bot 实现图床功能 项目地址 img-mom 功能特点 支持将图片上传到 Telegram 图床或其他支持的图床服务。 返回图片链接,支持多种格式(如 Markdown、HTML)。 可通过/settings指令设置其他图床服务。 使用方法 部署 Telegram Bot: 在 GitHub 上克隆img-mom项目。 配置config.json文件,填写 Telegram Bot Token 和 Channel ID。 使用 Docker 或其他方式部署项目。 使用 Bot 上传图片: 将图片发送给机器人,机器人会返回 Telegram 图床链接。 可通过/settings指令设置其他图床服务。 3. 结合 PicGo 和图床服务 功能特点 使用 PicGo 作为图床工具,支持多种图床服务。 可以通过配置支持 Telegram 图床的插件,实现图片上传并自动生成链接。 使用方法 安装 PicGo: 下载并安装 PicGo:PicGo 官网 配置图床服务: 安装支持 Telegram 图床的插件,如telegraph-image-uploader。在 PicGo 中配置图床服务,填写 API 地址和其他必要信息。 上传图片:打开 PicGo,选择需要上传的图片。上传完成后,PicGo 会生成图片链接,你可以复制并使用。 4. 使用 Telegraph API 功能特点 Telegraph 是 Telegram 提供的一个服务,可以上传图文并生成链接。 适用于图床需求,支持图片、视频等多种文件格式。 使用方法 使用 Telegraph API 上传图片: 创建一个 Telegram Bot 并获取 API Token。 使用 Telegraph API 上传图片,获取返回的图片链接。 示例代码(Python): import requestsdef upload_image_to_telegraph(image_path, api_token): url = "https://api.telegra.ph/upload" headers = {"Authorization": f"Bearer {api_token}"} files = {"file": open(image_path, "rb")} response = requests.post(url, headers = headers, files = files) if response.status_code == 200: return response.json()[0]["src"] else : return None # 示例使用api_token = "你的Telegram Bot Token" image_path = "本地图片路径" image_link = upload_image_to_telegraph(image_path, api_token) print("图片链接:", image_link)结合 Cloudflare Workers 部署: 使用 Cloudflare Workers 编写一个简单的 API,调用 Telegraph API 上传图片。 部署完成后,通过自定义域名访问图床工具。 注意事项 文件大小限制:Telegram 对图片大小有限制(最大 5MB),部分服务可能会自动压缩图片。 部署和配置:部分方案需要一定的技术基础进行部署和配置,例如设置 Cloudflare Workers、Telegram Bot 等。
-
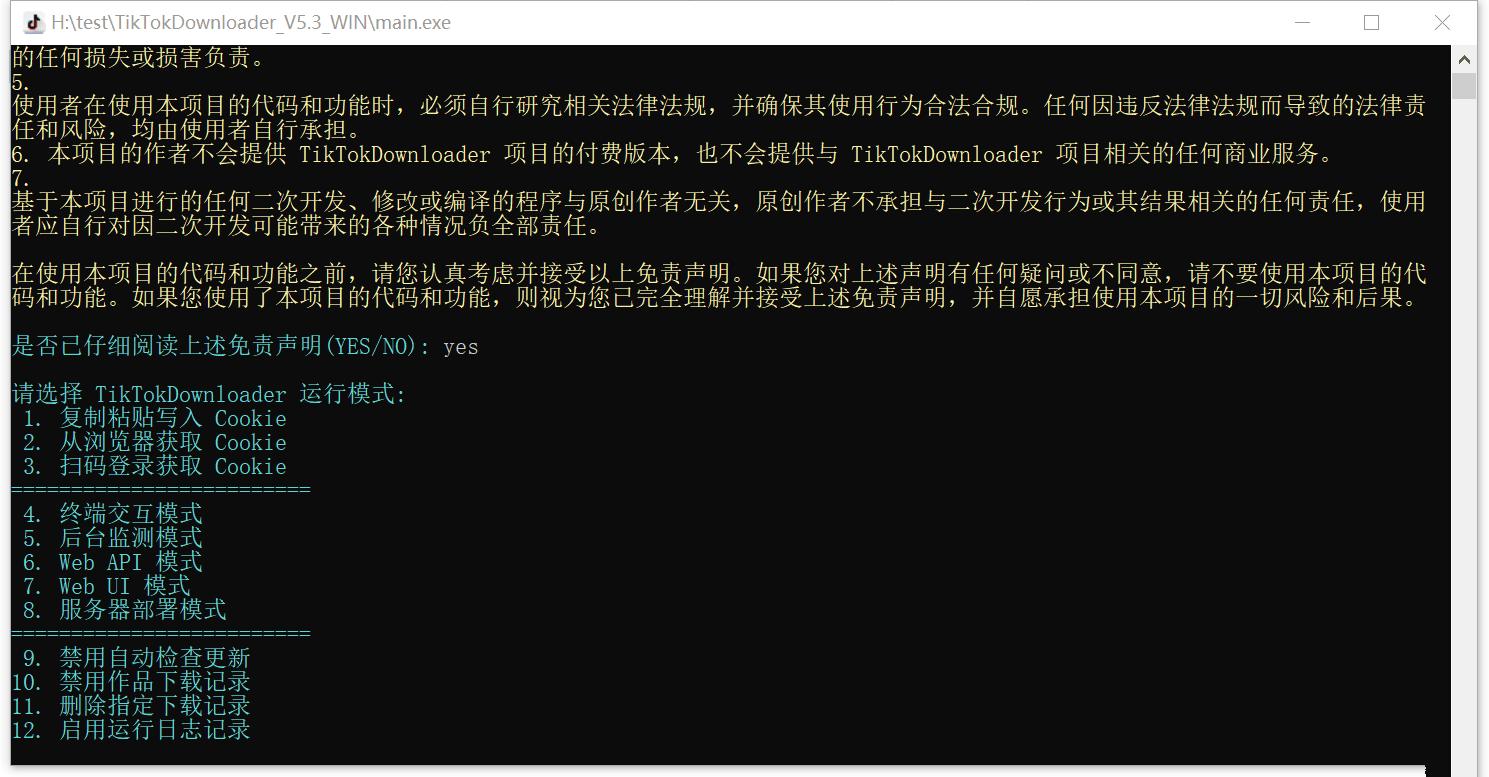
抖音采集下载工具 TikTokDownloader TikTokDownloader 是一个开源项目,功能强大的抖音数据采集工具。它支持多种功能,包括下载无水印视频、图集,采集抖音详细数据,以及获取直播推流地址等。 功能介绍 下载无水印视频/图集:轻松获取高清无水印内容。 批量下载作品:支持批量下载抖音账号发布的视频、喜欢的视频、收藏的作品。 采集详细数据:获取抖音视频的详细数据,方便分析和研究。 自动跳过已下载文件:避免重复下载,节省时间和空间。 持久化保存数据:采集的数据可以持久保存,方便后续查看。 下载封面图:支持下载动态和静态封面图。 获取直播推流地址:可以获取抖音直播的推流地址,方便观看。 Web UI 交互界面:简单易用,双击main.exe即可打开程序,按提示操作即可。 工具预览图 图片 图片 下载地址 隐藏内容,请前往内页查看详情 使用说明 配置 Cookie:使用前需要先配置 Cookie,具体操作请参考离线文档。 操作步骤:双击main.exe打开程序,按提示操作即可进入 Web UI 交互模式。
-
2025年蛇年大吉新年创意图模板PSD设计CDR素材 2025 年蛇年大吉新年创意图模板 PSD 设计 CDR 素材 新年到,蛇年大吉!为了让设计爱好者和创意工作者更好地迎接新年,今天为大家分享一套 2025 年蛇年新年创意图模板。这套素材包含 PSD 和 CDR 格式,适合各种设计需求,即使是设计新手也能轻松上手,快速制作出精美的新年海报、贺卡等。 素材亮点 多种格式:提供 PSD 和 CDR 格式,满足不同设计软件的使用需求。 创意元素:丰富的蛇年元素,让设计更具新年氛围。 易于上手:即使是设计新手,也能快速掌握,轻松制作出专业感十足的作品。 素材预览图 图片 下载地址 隐藏内容,请前往内页查看详情
-
PUBG内核透视追踪广角载具车加速稳定内核(3.60版本) 功能介绍 PUBG 3.60版本的内核透视追踪广角载具加速稳定内核,功能强大,一次购买永久使用,提升游戏体验。 永久使用 PUBG 玩家们,想要在游戏中获得更好的体验?今天为大家介绍一款 PUBG 的辅助工具——3.60 版本的内核透视追踪广角载具加速稳定内核。这款工具功能强大,一次购买,永久使用! 绘制功能 血量、方框、射线、距离、骨骼、人数、名称、载具、追踪射线、雷达、类名 清晰显示敌人信息,帮助你更好地掌握战场动态。 追踪功能 子弹追踪、掩体漏打、自动开火、360° 追踪 支持算法和函数自定义,可设置追踪距离和追踪概率,让你轻松锁定目标。 人物相关 广角、定点、加速、跳跃、死亡叫 提升人物操作灵活性,加速跳跃轻松上房,广角视野更开阔。 坐标相关 热气球、电梯、锁定地形、坐标传送 快速定位和传送,让你在游戏中更加便捷。 载具相关 载具控制、载具穿墙、自定义载具重力、速度、左右翻滚、前后翻滚 提升载具性能,无论是越野还是漂移,都能轻松应对。 下载地址 PUBG内核 下载地址:https://pan.baidu.com/s/1ATRfcfgBgdL71ovVDYHWQg?pwd=5x74 提取码:5x74 工具介绍图 图片