找到
295
篇与
易航
相关的结果
- 第 12 页
-
 你知道 Python 其实自带了小型数据库吗 DBM(DataBase Manager) DBM(DataBase Manager)是一种文件系统,专门用于键值对的存储,最初是在 Unix 平台实现,现在其它平台也可以用。对于 KV 模型,DBM 提供了一个轻量级、高效的存储解决方案。 总的来说,DBM 具有如下特点: 简单快速:非常简单易用,读取和写入操作都很快,适合存储少量数据。 键值对存储:数据是以键值对形式存储的,你可以像操作 Python 字典一样。 文件存储:数据存在具体的文件中,可以轻松地备份和转移。 不支持复杂查询:如果需要执行复杂查询或需要关系型数据库的功能,DBM 可能不是一个好选择。 而 Python 标准库提供了一个 dbm 模块,它实现了 DBM 文件系统的功能,来看一下它的用法。 import dbm # 第一个参数是文件名 # 第二个参数是模式,有以下几种 # r:只读,要求文件必须存在,默认就是这个模式 # w:可读可写,要求文件必须存在 # c:可读可写,文件不存在会创建,存在则追加 # n:可读可写,文件不存在会创建,存在则清空 # 第三个参数是权限,用八进制数字表示,默认 0o666,即可读可写不可执行 db = dbm.open("store", "c") # 打开文件就可以存储值了,key 和 value 必须是字符串或 bytes 对象 db["name"] = "S せんせい" db["age"] = "18" db[b"corporation"] = "小摩".encode("utf-8") # 关闭文件,将内容写到磁盘上 db.close()非常简单,就像操作字典一样,并且 key 是唯一的,如果存在则替换。执行完后,当前目录会多出一个 store.db 文件。 图片 我们打开它,然后读取刚才写入的键值对。 import dbm db = dbm.open("store", "c") # 获取所有的 key,直接返回一个列表 print(db.keys()) """ [b'corporation', b'name', b'age'] """ # 判断一个 key 是否存在,key 可以是字符串或 bytes 对象 print("name" in db, "NAME" in db) """ True False """ # 获取一个 key 对应的 value,得到的是 bytes 对象 print(db["name"].decode("utf-8")) print(db[b"corporation"].decode("utf-8")) """ S せんせい 小摩 """ # key 如果不存在,会抛出 KeyError,我们可以使用 get 方法 print(db.get("NAME", b"unknown")) """ b'unknown' """ # 当然也可以使用 setdefault 方法,key 不存在时,自动写进去 print(db.setdefault("gender", b"female")) """ b'female' """ print(db["gender"]) """ b'female' """非常简单,当你需要存储的数据量不适合放在内存中,但又没必要引入数据库,那么不妨试试使用 dbm 模块吧。 当然啦,dbm 虽然很方便,但它只能持久化 bytes 对象,字符串也是转成 bytes 对象之后再存储的。所以除了 dbm 之外,还有一个标准库模块 shelve,它可以持久化任意对象。 shelve shelve 的使用方式和 dbm 几乎是一致的,区别就是 shelve 的序列化能力要更强,当然速度自然也就慢一些。 import shelve # 第二个参数表示模式,默认是 c # 因此文件不存在会创建,存在则追加 sh = shelve.open("shelve") sh["name"] = ["S 老师", "高老师", "电烤🐔架"] sh["age"] = {18} sh["job"] = {"tutu": "大学生", "xueer": "医生"} # 关闭文件,刷到磁盘中 sh.close()执行完之后,本地会多出一个 shelve.db 文件,下面来读取它。 import shelve sh = shelve.open("shelve") print(sh["name"]) print(sh["name"][2] == "电烤🐔架") """ ['S 老师', '高老师', '电烤🐔架'] True """ print(sh["age"]) """ {18} """ print(sh["job"]) """ {'tutu': '大学生', 'xueer': '医生'} """ sh.close()读取出来的就是原始的对象,我们可以直接操作它。 然后自定义类的实例对象也是可以的。 import shelve class People: def __init__(self, name, age): self.name = name self.age = age @property def print_info(self): return f"name is {self.name}, age is {self.age}" sh = shelve.open("shelve") p = People("群主", 58) # 将类、和该类的实例对象存储进去 sh["People"] = People sh["p"] = p sh.close()执行完之后,我们打开它。 import shelve sh = shelve.open("shelve") # 需要注意的是,People 是我们自己定义的类 # 如果你想要将其还原出来,那么该类必须要出现在当前的命名空间中 try: sh["People"] except AttributeError as e: print(e) """ Can't get attribute 'People' on <module ...> """ class People: def __init__(self, name, age): self.name = name self.age = age @property def print_info(self): return f"name is {self.name}, age is {self.age}" print(sh["People"] is People) """ True """ print(sh["p"].print_info) """ name is 群主, age is 58 """ print(sh["People"]("群主", 38).print_info) """ name is 群主, age is 38 """这就是 shelve 模块,非常强大,当然它底层也是基于 pickle 实现的。如果你不需要存储复杂的 Python 对象,只需要存储字符串的话,那么还是推荐 dbm。 然后在使用 shelve 的时候,需要注意里面的一个坑。 import shelve # 打开文件,设置键值对 sh = shelve.open("shelve") sh["name"] = "古明地觉" sh["score"] = [80, 80, 80] sh.close() # 重新打开文件,修改键值对 sh = shelve.open("shelve") sh["name"] = "芙兰朵露" sh["score"].append(90) sh.close() # 再次重新打开文件,查看键值对 sh = shelve.open("shelve") print(sh["name"]) print(sh["score"]) """ 芙兰朵露 [80, 80, 80] """ sh.close()第一次打开文件创建两个键值对,第二次打开文件将键值对修改,第三次打开文件查看键值对。但是我们发现 sh["name"] 变了,而 sh["score"] 却没变,这是什么原因? 当我们修改 name 时,采用的是直接赋值的方式,会将原本内存里的值给替换掉。而修改 score 时,是在原有值的基础上做 append 操作,它的内存地址并没有变。 所以可变对象在本地进行修改,shelve 默认是不会记录的,除非创建新的对象,并把原有的对象给替换掉。所以 sh["score"].append(90) 之后,sh["score"] 仍是 [80, 80, 80],而不是 [80, 80, 80, 90]。 因为 shelve 没有记录对象自身的修改,如果想得到期望的结果,一种方法是把对象整体换掉。也就是让 sh["score"] = [80, 80, 80, 90],这样等于是创建了一个新的对象并重新赋值,是可行的。 或者你在打开文件的时候,多指定一个参数 writeback。 import shelve # 打开文件,设置键值对 sh = shelve.open("shelve") sh["name"] = "古明地觉" sh["score"] = [80, 80, 80] sh.close() # 重新打开文件,修改键值对 sh = shelve.open("shelve", writeback=True) sh["name"] = "芙兰朵露" sh["score"].append(90) sh.close() # 再次重新打开文件,查看键值对 sh = shelve.open("shelve") print(sh["name"]) print(sh["score"]) """ 芙兰朵露 [80, 80, 80, 90] """ sh.close()可以看到都发生改变了,但这个参数会导致额外的内存消耗。当指定 writeback=True 的时候,shelve 会将读取的对象都放到一个内存缓存当中。比如我们操作了 20 个持久化的对象,但只修改了一个,剩余的 19 个只是查看并没有做修改,但当 sh.close() 的时候,会将这 20 个对象都写回去。 因为 shelve 不知道你会对哪个对象做修改,所以不管你是查看还是修改,都会放到缓存当中,然后再一次性都写回去。这样就会造成两点影响: shelve 会把我们使用的对象放到内存的另一片空间中,等于是额外拷贝了一份。 虽然操作了 N 个对象,但只修改了 1 个,而 shelve 会把 N 个对象都重新写回去,从而造成性能上的问题,导致效率降低。 因此加不加这个参数,由具体情况决定。 综上所述,Python 算是自带了小型数据库,看看能不能在合适的场景中把它用上。
你知道 Python 其实自带了小型数据库吗 DBM(DataBase Manager) DBM(DataBase Manager)是一种文件系统,专门用于键值对的存储,最初是在 Unix 平台实现,现在其它平台也可以用。对于 KV 模型,DBM 提供了一个轻量级、高效的存储解决方案。 总的来说,DBM 具有如下特点: 简单快速:非常简单易用,读取和写入操作都很快,适合存储少量数据。 键值对存储:数据是以键值对形式存储的,你可以像操作 Python 字典一样。 文件存储:数据存在具体的文件中,可以轻松地备份和转移。 不支持复杂查询:如果需要执行复杂查询或需要关系型数据库的功能,DBM 可能不是一个好选择。 而 Python 标准库提供了一个 dbm 模块,它实现了 DBM 文件系统的功能,来看一下它的用法。 import dbm # 第一个参数是文件名 # 第二个参数是模式,有以下几种 # r:只读,要求文件必须存在,默认就是这个模式 # w:可读可写,要求文件必须存在 # c:可读可写,文件不存在会创建,存在则追加 # n:可读可写,文件不存在会创建,存在则清空 # 第三个参数是权限,用八进制数字表示,默认 0o666,即可读可写不可执行 db = dbm.open("store", "c") # 打开文件就可以存储值了,key 和 value 必须是字符串或 bytes 对象 db["name"] = "S せんせい" db["age"] = "18" db[b"corporation"] = "小摩".encode("utf-8") # 关闭文件,将内容写到磁盘上 db.close()非常简单,就像操作字典一样,并且 key 是唯一的,如果存在则替换。执行完后,当前目录会多出一个 store.db 文件。 图片 我们打开它,然后读取刚才写入的键值对。 import dbm db = dbm.open("store", "c") # 获取所有的 key,直接返回一个列表 print(db.keys()) """ [b'corporation', b'name', b'age'] """ # 判断一个 key 是否存在,key 可以是字符串或 bytes 对象 print("name" in db, "NAME" in db) """ True False """ # 获取一个 key 对应的 value,得到的是 bytes 对象 print(db["name"].decode("utf-8")) print(db[b"corporation"].decode("utf-8")) """ S せんせい 小摩 """ # key 如果不存在,会抛出 KeyError,我们可以使用 get 方法 print(db.get("NAME", b"unknown")) """ b'unknown' """ # 当然也可以使用 setdefault 方法,key 不存在时,自动写进去 print(db.setdefault("gender", b"female")) """ b'female' """ print(db["gender"]) """ b'female' """非常简单,当你需要存储的数据量不适合放在内存中,但又没必要引入数据库,那么不妨试试使用 dbm 模块吧。 当然啦,dbm 虽然很方便,但它只能持久化 bytes 对象,字符串也是转成 bytes 对象之后再存储的。所以除了 dbm 之外,还有一个标准库模块 shelve,它可以持久化任意对象。 shelve shelve 的使用方式和 dbm 几乎是一致的,区别就是 shelve 的序列化能力要更强,当然速度自然也就慢一些。 import shelve # 第二个参数表示模式,默认是 c # 因此文件不存在会创建,存在则追加 sh = shelve.open("shelve") sh["name"] = ["S 老师", "高老师", "电烤🐔架"] sh["age"] = {18} sh["job"] = {"tutu": "大学生", "xueer": "医生"} # 关闭文件,刷到磁盘中 sh.close()执行完之后,本地会多出一个 shelve.db 文件,下面来读取它。 import shelve sh = shelve.open("shelve") print(sh["name"]) print(sh["name"][2] == "电烤🐔架") """ ['S 老师', '高老师', '电烤🐔架'] True """ print(sh["age"]) """ {18} """ print(sh["job"]) """ {'tutu': '大学生', 'xueer': '医生'} """ sh.close()读取出来的就是原始的对象,我们可以直接操作它。 然后自定义类的实例对象也是可以的。 import shelve class People: def __init__(self, name, age): self.name = name self.age = age @property def print_info(self): return f"name is {self.name}, age is {self.age}" sh = shelve.open("shelve") p = People("群主", 58) # 将类、和该类的实例对象存储进去 sh["People"] = People sh["p"] = p sh.close()执行完之后,我们打开它。 import shelve sh = shelve.open("shelve") # 需要注意的是,People 是我们自己定义的类 # 如果你想要将其还原出来,那么该类必须要出现在当前的命名空间中 try: sh["People"] except AttributeError as e: print(e) """ Can't get attribute 'People' on <module ...> """ class People: def __init__(self, name, age): self.name = name self.age = age @property def print_info(self): return f"name is {self.name}, age is {self.age}" print(sh["People"] is People) """ True """ print(sh["p"].print_info) """ name is 群主, age is 58 """ print(sh["People"]("群主", 38).print_info) """ name is 群主, age is 38 """这就是 shelve 模块,非常强大,当然它底层也是基于 pickle 实现的。如果你不需要存储复杂的 Python 对象,只需要存储字符串的话,那么还是推荐 dbm。 然后在使用 shelve 的时候,需要注意里面的一个坑。 import shelve # 打开文件,设置键值对 sh = shelve.open("shelve") sh["name"] = "古明地觉" sh["score"] = [80, 80, 80] sh.close() # 重新打开文件,修改键值对 sh = shelve.open("shelve") sh["name"] = "芙兰朵露" sh["score"].append(90) sh.close() # 再次重新打开文件,查看键值对 sh = shelve.open("shelve") print(sh["name"]) print(sh["score"]) """ 芙兰朵露 [80, 80, 80] """ sh.close()第一次打开文件创建两个键值对,第二次打开文件将键值对修改,第三次打开文件查看键值对。但是我们发现 sh["name"] 变了,而 sh["score"] 却没变,这是什么原因? 当我们修改 name 时,采用的是直接赋值的方式,会将原本内存里的值给替换掉。而修改 score 时,是在原有值的基础上做 append 操作,它的内存地址并没有变。 所以可变对象在本地进行修改,shelve 默认是不会记录的,除非创建新的对象,并把原有的对象给替换掉。所以 sh["score"].append(90) 之后,sh["score"] 仍是 [80, 80, 80],而不是 [80, 80, 80, 90]。 因为 shelve 没有记录对象自身的修改,如果想得到期望的结果,一种方法是把对象整体换掉。也就是让 sh["score"] = [80, 80, 80, 90],这样等于是创建了一个新的对象并重新赋值,是可行的。 或者你在打开文件的时候,多指定一个参数 writeback。 import shelve # 打开文件,设置键值对 sh = shelve.open("shelve") sh["name"] = "古明地觉" sh["score"] = [80, 80, 80] sh.close() # 重新打开文件,修改键值对 sh = shelve.open("shelve", writeback=True) sh["name"] = "芙兰朵露" sh["score"].append(90) sh.close() # 再次重新打开文件,查看键值对 sh = shelve.open("shelve") print(sh["name"]) print(sh["score"]) """ 芙兰朵露 [80, 80, 80, 90] """ sh.close()可以看到都发生改变了,但这个参数会导致额外的内存消耗。当指定 writeback=True 的时候,shelve 会将读取的对象都放到一个内存缓存当中。比如我们操作了 20 个持久化的对象,但只修改了一个,剩余的 19 个只是查看并没有做修改,但当 sh.close() 的时候,会将这 20 个对象都写回去。 因为 shelve 不知道你会对哪个对象做修改,所以不管你是查看还是修改,都会放到缓存当中,然后再一次性都写回去。这样就会造成两点影响: shelve 会把我们使用的对象放到内存的另一片空间中,等于是额外拷贝了一份。 虽然操作了 N 个对象,但只修改了 1 个,而 shelve 会把 N 个对象都重新写回去,从而造成性能上的问题,导致效率降低。 因此加不加这个参数,由具体情况决定。 综上所述,Python 算是自带了小型数据库,看看能不能在合适的场景中把它用上。
-
PDF编辑神器 PDF编辑起来SoEasy 已有9.4K Star! 在数字化办公和学习的今天,PDF文件因其便携性和稳定性成为了文档交换的主要格式。然而,处理PDF文件时,我们常常需要一款功能强大而又免费的软件来应对各种编辑需求。今天,就让我们来深入了解一下开源项目PDFPatcher,一个拥有9.4K Star的PDF处理工具,它将如何帮助我们高效地处理PDF文件。软件介绍 图片 PDFPatcher,昵称“PDF补丁丁”,是一个.NET开发的开源PDF处理工具。它以其强大的功能和用户友好的界面,在GitHub上获得了9.4K的高星评价。这个项目不仅免费,而且承诺无广告、无弹窗,尊重用户隐私。特点 PDFPatcher的最大特点在于其全面而深入的PDF编辑能力。它不仅仅是一个简单的查看器,而是一个真正的PDF文件“手术刀”,能够对PDF文档进行精细的修改和重组。主要功能 图片 修改PDF文档属性、页码编号、页面链接,统一页面尺寸,删除自动打开网页等动作。 去除复制及打印限制,设置阅读器初始模式,清理文档隐藏垃圾数据。 贴心PDF书签编辑器,支持批量修改书签属性,精确定位页面,执行查找替换。 制作PDF文件,合并已有PDF文件或图片,生成新的PDF文件,并自定义书签。 拆分或合并PDF文件,并保留或添加书签。 高速无损导出PDF文档的图片,将PDF页面转换为图片。 提取或删除PDF文档中指定的页面,调整PDF文档的页面顺序。 根据PDF文档元数据重命名PDF文件名,调用微软Office的图像识别引擎分析PDF文档图片中的文字。 怎么安装使用 PDFPatcher的安装和使用非常简单。用户只需从官方网站或GitHub仓库下载软件压缩包,解压后即可运行。由于它是便携式的,无需安装即可使用所有功能。图片 下载地址 隐藏内容,请前往内页查看详情 总结 PDFPatcher以其开源、免费、功能全面的特点,在众多PDF处理工具中脱颖而出。它不仅满足了基本的PDF阅读和编辑需求,还提供了高级的文档结构分析和书签管理功能,是每个需要处理PDF文件的用户不可或缺的工具。
-
码支付:Thinkphp 框架个人不能支付新势力,个人收款开源革命 亲测可以使用感兴趣的同学可以下载研究下, 收款还是比较麻烦的线上,可以使用这个系统解决,实现个人码支付 支持个人微信赞赏码,微信支付二维码 还支付对接收钱吧的二维码 码支付[mPay]以其轻巧身姿,为个人收款领域带来一场开源革命。这不仅仅是一款工具,它是你步入便捷收款新纪元的钥匙。基于新款Thinkphp框架开发,[mPay]源码现已开放,为你的个人收款需求提供强大支持, 源码已经打包放在下面,可以自行获取 图片 图片 个人收款,从未如此简单 [mPay],一款专为个人免签收款设计的神器,通过普通收款码即可实现收款通知自动回调,无缝对接绝大多数商城系统。目前,[mPay]仅提供个人版,开源且免费使用,是你个人财务自由的得力助手。 源自源支付,超越源支付 [mPay]在源支付的设计思路上进行了革新,采用第四方聚合收款码,确保收款的稳定性与便捷性。个人申请聚合收款码无需资质,无需API接口,选择众多实力雄厚的收银服务平台(如拉卡拉、收钱吧等),让你的收款无后顾之忧。 特点突出,收款无忧 免监听 :告别挂机监听,[mPay]通过设置定时任务即可实现支付回调。 多环境支持 :全面支持微信、支付宝、云闪付的H5环境,长按识别扫码支付,域名防红。 稳定安全 :个人搭建的收款系统,收款稳定,安全可控,无需支付额外手续费。 多平台支持 :支持多平台(聚合码服务商)、多账号(聚合码商户)、多渠道(门店码/店员码/桌号码等),有效降低异地线上收款风控风险。 内置插件,即装即用 微信插件wxpay :默认安装,支持赞赏码、个人码|经营码|商家码,提供两个通道,需挂机监听。 支付宝插件alipay :默认安装,支持收钱码、经营码,两个通道,需挂机监听。 收钱吧聚合码插件sqbpay :默认安装,无需挂机,设置定时任务即可。 技术架构,前沿高效 [mPay]采用Thinkphp8框架,推荐PHP版本8.2,前端UI采用Layui 2.9+PearAdmin后台,为你提供一个既前沿又高效的技术架构。 码支付[mPay],不仅是技术的突破,更是个人收款自由的象征。现在就来体验[mPay],开启你的个人收款新篇章 功能 收款还是比较麻烦的线上,可以使用这个系统解决,实现个人码支付 支持个人微信赞赏码,微信支付二维码 还支付对接收钱吧的二维码 码支付[mPay]以其轻巧身姿,为个人收款领域带来一场开源革命。这不仅仅是一款工具,它是你步入便捷收款新纪元的钥匙。基于新款Thinkphp框架开发,[mPay]源码现已开放,为你的个人收款需求提供强大支持, 源码下载 隐藏内容,请前往内页查看详情
-
讲讲怎么规避脏东西的干扰 这几天帮人许愿,发现好几位的心愿都是远离鬼魅精怪呀,附体之类的脏东西。 这其实很简单,我讲一个实修层面的技术,不需要基础,人人都能做到。 我还是主张,多建设,少破坏,多给祖师爷添产业。可以掀桌,不能砸锅。 掀桌是为了平等吃饭,砸锅就都没饭吃了。 一句话概括重点,一个人会被脏东西干扰是因为不能正眼瞧它们。 最近几个月因为抽旱烟杆,装填清洗非常麻烦,就干脆设置在我卫生间的洗手台前。于是我每天抽烟的时候都必然会照镜子。 恰好最近在参我们净明道玉真祖师真诀中照心的问题。 我发现我看着镜子中的自己是不会起情绪的。 这是正常状态,大部分人看镜子中的自己或者自己的照片都不会起情绪。心态良好,一个人看自己的至亲,结婚多年的伴侣也不会起情绪,就像看自己一样。 俗话说中年夫妻手牵手,就像左手牵右手。指的就是这种情况。关系正常的,中年夫妻就应该把对方看得像自己一样。对方的手自然也就像自己的手一样。 有修为的人。这个范围可以继续扩大,看更多的人,甚至看所有人都像看自己一样不起情绪。 比如老师看所有的学生。王道偶像看所有的粉丝。神职人员看所有的信众。追求的目标和理想状态都是看所有人都一样。 反之不理想的状态就是会用情绪看别人,而不是像看自己一样看别人。 面对一个人,大概率或多或少会有一种情绪,喜欢,厌恶,尊重,鄙夷,谄媚,欺侮。 这都是用情绪看人。也就是不正眼看人。 我们再延伸到玄学领域。长期住庙的道友都知道,信众面对于神像,什么状态都有。有心生欢喜,控制不住笑出声的。有嚎啕大哭的。有恐惧害怕浑身发抖的。 有满地打滚的。有骂骂咧咧的。 这些都是最生动的例子,他们在拿情绪看神。 正常情况或者是住庙时间长的道友。天天看,看习惯了,自然心态平和,像看自己一样看神像,这就是正眼看神。 欢喜也不是什么好事,有欢喜必有厌恶,这是一体两面。 对脏东西也是一样。只不过受到困扰的人一定会用负面情绪看待脏东西,或者恐惧或者厌恶。如果遇到这脏东西,心生喜悦,那就不是困扰了。 吸引脏东西,给脏东西可乘之机的不是人,而是负面情绪。解决问题的根源是让自己正眼看脏东西,他们就没有可乘之机,你对他们也没有吸引力了。 把逻辑往前倒。凡是有这种困扰或者自己很容易招脏东西的人。你照照镜子试试,对着镜子里的自己看几分钟,内观其心,看自己对自己起不起情绪。 这样的人往往对自己都有一大堆情绪。而且是负面情绪,看自己不顺眼,看自己一大堆毛病。痛恨自己为什么不长这样,为什么不是那样?对自己恨铁不成钢。厌恶自己。厌恶自己与生俱来的很多属性。 看自己都带情绪的人,怎么可能不带情绪看别人。怎么可能不带情绪看神仙祖师。不带情绪看脏东西。 正道神仙属阳,脏东西属阴。正面情绪属阳,负面情绪属阴。阳这个抽象概念的本体就是太阳,阴这个抽象概念的本体就是月亮。 太阳是个等离子体,在古代没有这些概念,只能管它叫炁体。月亮就是个石头疙瘩。假设一个人无限接近太阳,他一定会在某一个距离气化,然后等离子化,然后他就会成为太阳的一部分,其中一部分光可能会照到地球上,那就是烧这个人产生的光。 但如果一个人无限接近月亮,那最后他会砸在月亮上,他不会成为月亮的一部分,只会成为月亮上的垃圾。 这就是阴阳的区别,所以亲近阳属性的人和事物会获取能量,而且对对方没有影响。一个人烤火和十个人烤火对于篝火来说是一样的。 亲近阴属性的人和事物,最后结果就是硬碰硬,谁弱谁受伤。 对于普通的人而言,最理想的状态是站在太阳和月亮中间,然后面朝太阳。 这是个比喻。 对于受到脏东西困扰的人,很多野生心理学家和灵修体系,会跟他强调,爱与光明之类的,甚至说多晒太阳。也是这个路子。 最简单最直接的方法就是从情绪下手,多照镜子,先把自己看顺眼。再把自己身边的至亲看顺眼。如果一个人能正眼看自己不起情绪,正眼看家人至亲伴侣不起情绪。就足够不受脏东西的困扰了。 只要看的时间长,刻意训练不起情绪,都能看顺眼的。对着镜子多找找自己的长处,多找找自己和大多数人一样的地方。 绝大多数人的禀赋都是相近的,都是普通人,各方面都是各有长短。 说相声的都跟郭德纲比,那早晚得气死。找到自己的艺术风格也可以说得很开心。 人都是这样。不要总想着斩妖除魔,请符做法护身,自己心态好一点,脏东西接近你的性价比低到一定程度,自然就会远离。这就是中医的思维方式,也是大道的思维方式。 这些年我发现一个有意思的规律,有很多直接或间接的关系,说好和我见面的,后来由于种种变故,而没有和我见面。过一段时间,大多能听说他被各式各样的脏东西困扰,或者给身边的人带来困扰。其实不是他不愿见我,而是脏东西结合负面情绪共同作用,生出变故来避免见我。 发展才是硬道理,烦请转发给需要的人吧。谢谢大家。
-
提升 PHP 代码质量:命名参数的最佳实践与示例 还在为PHP函数中繁多的参数和它们代表的含义而烦恼吗?还在费力数逗号以确保参数顺序正确吗?PHP 8.0 的命名参数将帮你解决这些问题!本指南将带你了解命名参数的概念、使用方法以及如何利用它们提升代码质量。 图片 什么是命名参数? 命名参数允许你通过指定参数名称,而不是依赖参数顺序,来向函数传递值。就像给每个参数都贴上了标签,代码因此更易读、更不易出错,避免了参数含义混淆不清的情况。 新旧方法对比 让我们来看一个电商应用中的实际例子,假设你正在构建一个创建新产品的功能: function createProduct( string $name, float $price, string $category, bool $inStock = true, int $quantity = 0, array $tags = [], string $description = '' ) { // 产品创建逻辑 } // 旧方法(位置参数) createProduct( '游戏鼠标', 49.99, '电子产品', true, 100, ['游戏', '配件'], '带 RGB 照明的高性能游戏鼠标' );如果不去查看函数定义,很难一眼看出上面代码中每个参数值的含义。现在,让我们看看命名参数是如何提高代码清晰度的: // 新方法(命名参数) createProduct( name: '游戏鼠标', price: 49.99, category: '电子产品', quantity: 100, tags: ['游戏', '配件'], description: '带 RGB 照明的高性能游戏鼠标' );命名参数的好处 提高代码可读性 命名参数本身就是一种代码文档。任何阅读代码的人都能立刻理解每个值的含义,无需再去查看函数定义。 跳过可选参数 使用命名参数,你可以跳过那些不需要设置的可选参数。 示例如下: function sendEmail( string $to, string $subject, string $body, ?string $replyTo = null, bool $isHtml = true, int $priority = 3 ) { // 电子邮件发送逻辑 } // 仅设置您需要的参数 sendEmail( to: 'customer@example.com', subject: 'Order Confirmation', body: $emailContent, priority: 1 // 跳过 replyTo和isHtml,使用其默认值 );参数顺序不再重要 使用命名参数时,参数的顺序不再重要。这种灵活性让代码维护更加轻松: // These are equivalent: sendEmail( body: $emailContent, subject: '订单确认', to: 'customer@example.com' ); sendEmail( to: 'customer@example.com', subject: '订单确认', body: $emailContent );混合使用命名参数和位置参数 你可以混合使用命名参数和位置参数,但需要注意:一旦开始使用命名参数,其后的所有参数也都必须使用命名参数: function createUser( string $username, string $email, string $password, bool $isAdmin = false, ?string $department = null ) { // 用户创建逻辑 } // Valid - positional arguments first, then named createUser( 'johnsmith', // username (位置) 'john@example.com', // email (位置) password: 'secure123', // 命名参数从这里开始 department: 'Sales' // 命名 );最佳实践 为了提高代码清晰度,当函数参数较多,或者参数的用途不容易从值本身判断时,请使用命名参数。 布尔值参数尤其适合使用命名参数,因为true或false本身并不能清晰地表达其含义。 // 不清楚 createUser('john', 'john@example.com', 'password123', true); // 更清楚 createUser( username: 'john', email: 'john@example.com', password: 'password123', isAdmin: true ); 保持一致性:如果在函数调用中使用命名参数,建议为所有参数命名以保持一致,除非开头几个参数的含义在上下文中非常清晰。 清晰的参数命名:由于参数名称现在是函数公共接口的一部分,请务必选择清晰且具有描述性的名称。 常见陷阱 避免在使用命名参数后混合使用位置参数:一旦开始使用命名参数,其后的所有参数也都必须使用命名参数。 // 将导致错误 createUser(username: 'john', 'john@example.com', password: 'secret'); // 正确 createUser(username: 'john', email: 'john@example.com', password: 'secret'); 注意参数名称的修改:重构代码时,如果修改了参数名称,那么使用旧参数名称的命名参数调用将会失效。请记住,参数名称现在是公共 API 的一部分。 结论 命名参数是 PHP 的一项强大功能,它能够显著提升代码的可读性、可维护性和正确性。当函数拥有多个可选参数,或者参数的含义不容易从值本身判断时,命名参数将尤为有用。 在你的 PHP 8+ 项目中积极采用命名参数,尤其是在它能够提升代码清晰度的地方。未来的你(以及你的同事)都会感激你写出了更具自解释性和可维护性的代码。 记住:优秀的代码不仅仅是能够正常工作,更要清晰易懂且易于维护。命名参数正是你编写高质量 PHP 代码的利器之一。
-
PHP自建MD5解密平台 使用 PHP 构建 MD5 彩虹表生成器的完整过程 在信息安全领域,彩虹表(Rainbow Table) 是一种通过预计算哈希值和对应原始值的方式来破解密码的工具。为了实现一个简单高效的 MD5 彩虹表生成器,我使用了 PHP 和 MySQL,本文将详细介绍整个实现过程,并深入探讨如何解决开发中遇到的问题。 项目背景和需求 在项目的初始阶段,我们需要一个自动化生成 MD5 彩虹表的工具,并将生成的数据存储在 MySQL 数据库中。主要功能包括: 批量生成 MD5 哈希和对应的原始字符串 去重处理,避免重复存储相同的 MD5 哈希 可扩展性,支持任意字符集和字符串长度。 高效插入数据,避免性能瓶颈。 然而,在实现的过程中遇到了两个关键问题: 每次刷新页面时,因没有去重导致重复数据大量生成。 设置批量生成的目标条数(如 10,000 条),但数据量却无法稳定在目标值。 接下来,我们将详细拆解整个解决方案和代码实现。 环境准备 确保开发环境的搭建,包括: PHP 7.x或更高版本 MySQL 5.x或更高版本 Apache或Nginx服务器 数据库设计 在生成彩虹表之前,我们需要设计存储数据的数据库表。 数据表结构 表名为 rainbow_table,包含以下字段: id: 自增主键,用于标识每条记录。s hash: 存储 MD5 哈希值。 original: 存储原始字符串。 unique_hash: 创建唯一约束,确保哈希值不重复。 SQL 表的创建代码如下: CREATE TABLE rainbow_table ( id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY, hash VARCHAR(32) NOT NULL, original VARCHAR(255) NOT NULL, UNIQUE KEY unique_hash (hash) );如果表不存在,我们会在 PHP 脚本中动态创建它,确保代码的鲁棒性。 PHP 脚本实现 核心逻辑概述 字符集配置:可以自由定义生成字符串所使用的字符集,包括大小写字母、数字和特殊符号。 随机生成字符串:通过随机组合字符,生成指定长度的字符串。 MD5 哈希计算:将随机字符串计算为 MD5 哈希值。 数据插入与去重:使用 INSERT IGNORE 避免重复插入。 批量生成与页面自动刷新:每次生成一定数量的数据后自动刷新页面,持续生成。 完整 PHP 代码如下: <?php $servername = "localhost"; $username = "md5"; $password = "123456"; $dbname = "md5"; $tableName = "rainbow_table"; // 创建数据库连接 $conn = new mysqli($servername, $username, $password, $dbname); // 检查连接是否成功 if ($conn->connect_error) { die("连接失败: " . $conn->connect_error); } // 检查表是否存在,如果不存在则创建 $tableExists = $conn->query("SHOW TABLES LIKE '$tableName'")->num_rows > 0; if (!$tableExists) { $createTableSql = "CREATE TABLE $tableName ( id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY, hash VARCHAR(32) NOT NULL, original VARCHAR(255) NOT NULL, UNIQUE KEY unique_hash (hash) )"; if ($conn->query($createTableSql) === TRUE) { echo "表 $tableName 创建成功<br>"; } else { die("创建表错误: " . $conn->error); } } // 彩虹表生成函数 function generateRainbowTable($charset, $batchSize, $conn, $tableName) { $charsetLength = strlen($charset); $count = 0; $maxLength = 18; // 设置随机字符串最大长度 while ($count < $batchSize) { // 随机生成字符串长度 $length = rand(1, $maxLength); $count += generateRandomCombination($charset, $length, $charsetLength, $conn, $batchSize - $count, $tableName); } echo "生成了 $count 条记录\n"; } function generateRandomCombination($charset, $length, $charsetLength, $conn, $remaining, $tableName) { if ($remaining <= 0) return 0; $currentString = ''; for ($i = 0; $i < $length; $i++) { $currentString .= $charset[rand(0, $charsetLength - 1)]; } $hash = md5($currentString); // 使用 INSERT IGNORE 避免重复插入 $stmt = $conn->prepare("INSERT IGNORE INTO $tableName (hash, original) VALUES (?, ?)"); $stmt->bind_param("ss", $hash, $currentString); $stmt->execute(); return $stmt->affected_rows > 0 ? 1 : 0; } // 配置 $charset = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789.@#*?!$%^&()-_=+[]{}|;:,.<>~'; // 定义字符集 $batchSize = 2000; // 每次生成 2000 条 generateRainbowTable($charset, $batchSize, $conn, $tableName); $conn->close(); ?>关键点解析 1. 随机生成字符串 $length = rand(1, $maxLength); $currentString .= $charset[rand(0, $charsetLength - 1)];使用 rand() 随机生成字符串长度,再通过字符集随机组合字符,生成目标字符串。 2. 避免重复插入 $stmt = $conn->prepare("INSERT IGNORE INTO $tableName (hash, original) VALUES (?, ?)");使用 INSERT IGNORE 确保插入数据时,遇到重复哈希值会自动跳过,避免浪费资源。 3. 批量生成与计数 $count += generateRandomCombination($charset, $length, $charsetLength, $conn, $batchSize - $count, $tableName);每次生成一定数量的数据,直到达到目标批量数量。 前端自动刷新页面 为了实现自动化生成,我们在前端页面使用 JavaScript 设置定时刷新,每次刷新生成一批数据: <script> // 页面加载完成后自动刷新 window.onload = function() { setTimeout(function() { location.reload(); }, 1000); // 1秒后刷新页面 }; </script>通过这种方式,可以在页面刷新时持续调用生成函数,直到数据库存储满足预期需求。 问题与优化方案 问题 1:重复数据导致效率低下 最初代码未去重,每次刷新生成的大量数据包含重复项,浪费了存储和计算资源。通过添加 INSERT IGNORE 和数据库唯一索引,解决了此问题。 问题 2:生成数据量不足 由于生成逻辑中可能因重复数据导致插入失败,数据总量无法达到目标条数。通过调整随机生成逻辑,确保生成字符串更加分散,提高了数据覆盖率。 结论 本文通过详细介绍一个 PHP 实现的 MD5 彩虹表生成器,展示了从数据库设计到代码优化的完整流程。通过随机生成字符串、去重插入以及前端自动刷新机制,实现了高效的批量生成工具。 该工具不仅适用于 MD5,还可拓展为其他哈希算法生成器(如 SHA-1 或 SHA-256)。未来可进一步优化数据生成算法,提高生成速度和覆盖范围。 最后我的MD5解密平台:隐藏内容,请前往内页查看详情 图片 项目地址 隐藏内容,请前往内页查看详情
-
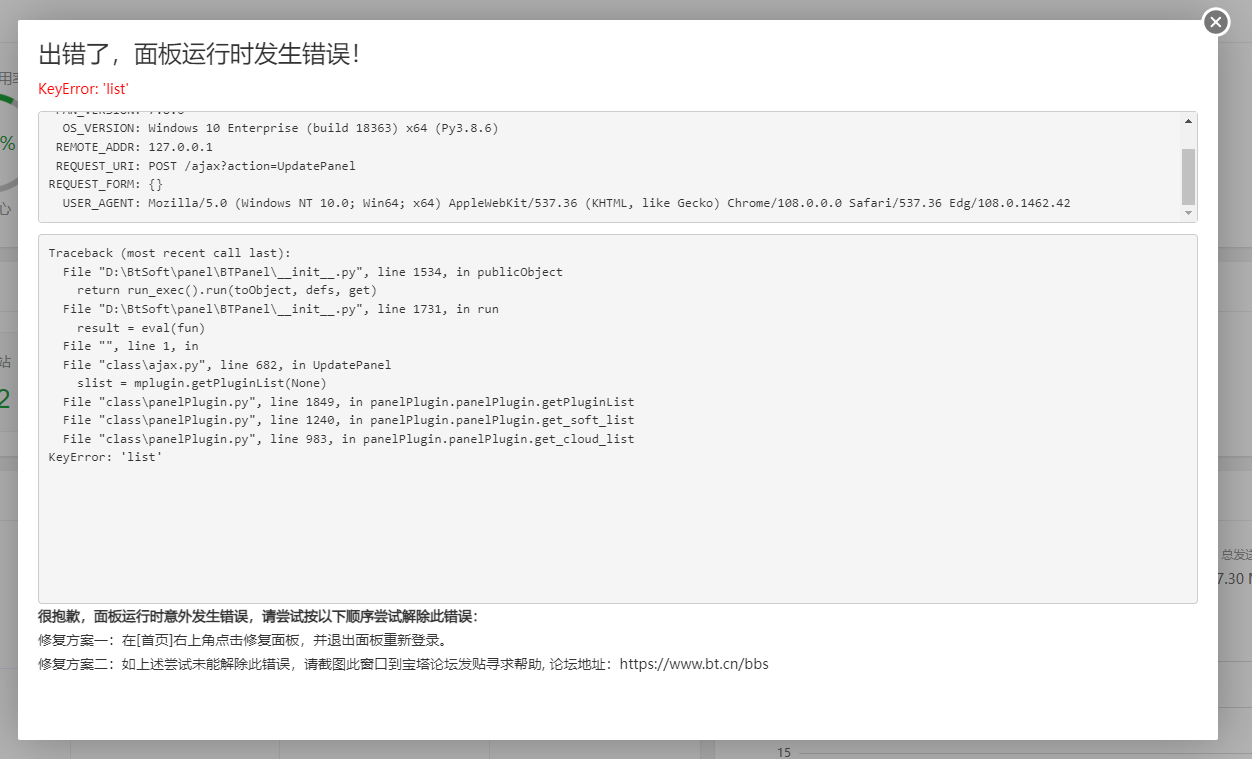
解决 Windows 宝塔面板报错 KeyError: ‘list’ Windows 宝塔面板 7.7.0 以上版本报错 KeyError: 'list' 是因为 7.7.0 以上的版本不再支持 Windows 家庭版的使用,并且根据我当时修复报错文件 panelPlugin.py 时发现 7.7.0 以上的版本时没有这个文件的,只有被编译好的不能反编译的 panelPlugin.pyd 文件,也就是说 Windows 宝塔 7.7.0 以上版本不再是开源面板,而宝塔官方给出的解决方案是安装 Windows 服务器版本虚拟机,但是这样不仅麻烦而且会占用电脑的性能,目前根据我在网上搜集到的信息结合自己的摸索总结出两个解决方案 图片 方案一 先使用 Shell 命令对宝塔面板进行降级到 7.7.0 版本 隐藏内容,请前往内页查看详情 降级到 7.7.0 版本后可以再使用 Shell 命令对宝塔面板升级到 8.1.0 版本,而后将不再会提示报错内容 隐藏内容,请前往内页查看详情 当然也可以只使用 7.7.0 版本 方案二 手动对宝塔面板进行降级到 7.7.0 版本,将文件 panel_7.7.0.zip 解压到宝塔安装目录的 panel 目录下 官方下载链接:隐藏内容,请前往内页查看详情 我自己备份的包:隐藏内容,请前往内页查看详情 然后再手动下载 8.1.0 版本的 panel_8.1.0.zip 文件解压到宝塔安装目录的 panel 目录下 官方下载链接:隐藏内容,请前往内页查看详情 我自己备份的包:隐藏内容,请前往内页查看详情
-
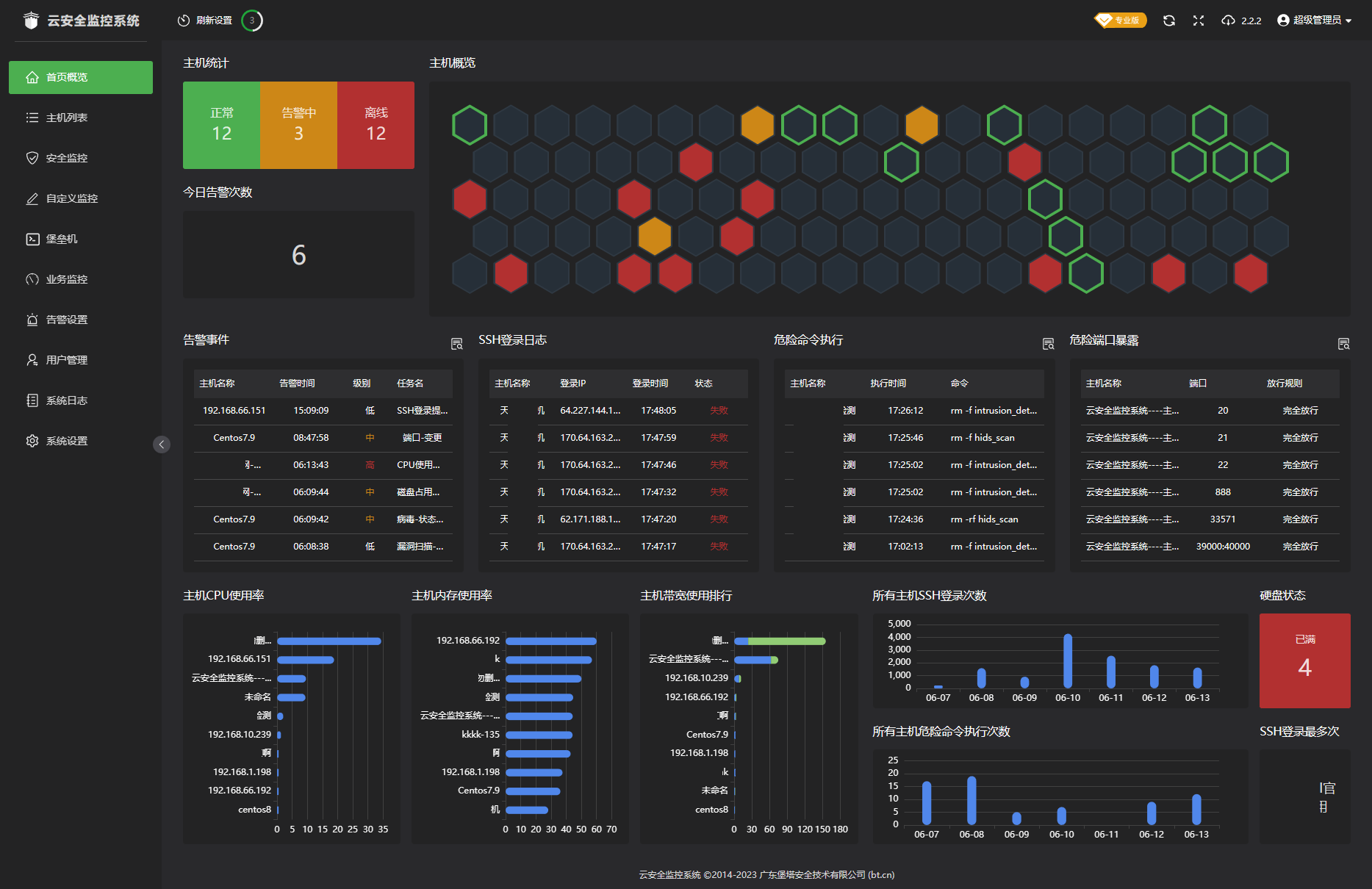
堡塔云监控 V2.3.0 开心版 花几分钟就能开始监控你的服务器安全性、一键扫描服务器集群病毒、漏洞、挖矿木马。 作为堡垒机批量管理你的服务器SSH终端、面板,操作录像回放,方便审计。 24小时监控,实时发送告警(支持飞书、钉钉、企业微信、邮件)帮助运维人员快速定位故障。 图片 简述: 云安全监控系统由云安全监控主控端与被监控端组成。 云安全监控主控端用于管理被监控端,查看、接收被监控端的数据,告警通知。 简称:主控 被监控端安装在被监控的服务器上采集数据。 简称:被控 云安全监控系统基本架构图: 图片 具体详细介绍请看官方帖子:https://techape.oss-cn-hangzhou.aliyuncs.combt.cn/bbs/thread-97800-1-1.html 安装云监控主控端 全新安装-云监控主控端执行以下命令安装云监控主控端开心版 隐藏内容,请前往内页查看详情 已安裝 – 官方雲監控主控端 執行以下命令 升級官方雲監控主控端(已安裝官方版升級爲開心版) 隐藏内容,请前往内页查看详情
-
HeyForm – 开源表单系统 可自托管 HeyForm 是一个开源的表单系统,可以用来收集调查、问卷、用户提交的数据等,比如在发现频道经常有开发者需要收集用户邮箱,使用回帖会对其他用户造成干扰,而使用表单就非常方便。 图片 这类工具还有腾讯文档的收集表功能,最终效果也是差不多的。只不过 HeyForm 可以自托管、支持逻辑跳转、可以添加变量、隐藏字段等,以及页面更加漂亮。非常适合高级用户及开发者。 HeyForm 能够通过 HeyForm 收集的数据非常多: 图片 你可以在后台通过拖拽,设置非常复杂的表单: 图片 你可以设置隐藏字段,变量,以及为每一个问题设置规则,比如设置一个评分规则,当分值大于5时,给另外一个变量「好评」加一,这样就能快速得到获得最多好评的数据。 另外这里也可以设置满足条件后直接跳转到另外一个问题。 图片 当然 HeyForm 的另外一个优势,就是自带的样式已经很漂亮了: 图片 所以,还是开头那句话,非常适合高级用户及开发者。不然很多平替,何必折腾。 获取 隐藏内容,请前往内页查看详情